 关于我
关于我
Flink DataStream API-概念、模式、作业流程和程序
前几篇介绍了Flink的入门、架构原理、安装等,相信你对Flink已经了解入门。接下来开始介绍Flink DataStream API内容,先介绍DataStream API基本概念和使用,然后介绍核心概念,最后再介绍经典案例和代码实现。本篇内容:Flink DataStream API的概念、模式、作业流程和程序。
1、基本概念
用于处理数据流的API称之为DataStream API,而DataStream类用于表示Flink程序中的数据集合。你可以将它视为包含重复项的不可变数据集合。这些数据可以是有限的,也可以是无限的,用于处理这些数据的API是相同的。
DataStream数据集都是分布式数据集,分布式数据集是指:一个数据集存储在不同的服务器节点上,每个节点存储数据集的一部分,例如下图:
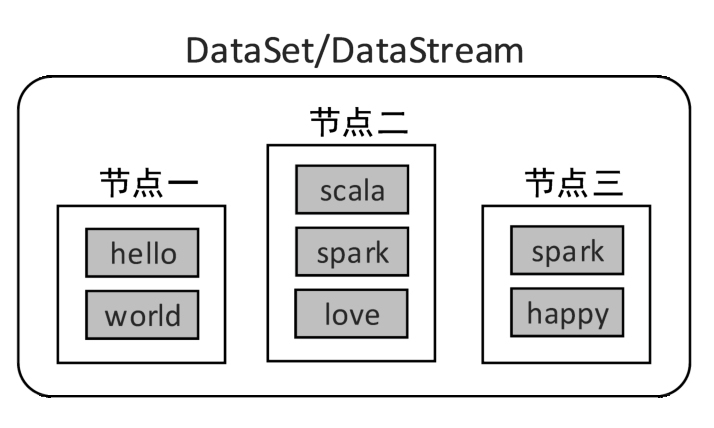
在编程时,可以把DataStream看作一个数据操作的基本单位,而不必关心数据的分布式特性,Flink会自动将其中的数据分发到集群的各个节点。
2、执行模式
Flink的执行模式分为3种:
- STREAMING:典型的DataStream执行模式(默认)
- BATCH:在DataStream API上以批处理方式执行
- AUTOMATIC:让系统根据数据源的有界性来决定
3、作业流程和程序结构
3.1、Flink作业流程
前面我们介绍过Flink JobManager是Flink集群的主节点,它包含3个不同的组件:Flink Resource Manager、Dispatcher、运行每个Flink Job的JobMaster。JobManager和TaskManager被启动后,TaskManager会将自己注册给JobManager中的ResourceManager(资源注册)。
Flink作业流程如下:
- 用户编写应用程序代码,并通过Flink客户端提交作业。,调用Flink API构建逻辑数据流图,然后转为作业图JobGraph,并附加到StreamExecutionEnvironment中。代码和相关配置文件被编译打包,被提交到JobManager的Dispatcher,形成一个应用作业。
- Dispatcher(JobManager的一个组件)接收到这个作业,启动JobManager,JobManager负责本次作业的各项协调工作。
- 接下来JobManager向ResourceManager申请本次作业所需的资源。
- JobManager将用户作业中的作业图JobGraph转化为并行化的物理执行图,对作业并行处理并将其子任务分发部署到多个TaskManager上执行。每个作业的并行子任务将在Task Slot中执行。至此Flink作业就开始执行了
- TaskManager在执行计算任务的过程中可能会与其他TaskManager交换数据,会使用相应的数据交换策略。同时,TaskManager也会将一些任务状态信息反馈给JobManager,这些信息包括任务启动、运行或终止的状态、快照的元数据等。
Flink作业流程图见下图:

3.2、Flink程序结构
前面我们介绍过,Flink的程序是有固定模板的,具体如下:
- 获取执行环境
- 加载/创建初始数据
- 对初始数据进行转换
- 指定计算结果的输出位置
- 触发程序执行
所有Flink程序都是**延迟(惰性)**执行的:执行程序的main()方法时,不会直接进行数据加载和转换,而是将每个操作添加到数据流图,当在执行环境中调用execute()显式触发执行时才会执行这些操作。程序是在本地执行还是在群集上执行取决于执行环境的类型。惰性计算允许构建复杂的程序,Flink将其作为一个整体规划的单元执行。
Flink的程序模板见下面的示例。示例采用流计算,读取socket数据源,对输入的数据进行统计,最后输出到控制台。执行main方法前,现在本地开启netcat,nc -lk 9999,然后输入任意字符,即可看到统计结果。
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据源
DataStream<String> textStream = env.socketTextStream("localhost", 9999, "\n");
// 3. 数据转换
DataStream<Tuple2<String, Integer>> wordCountStream = textStream
// 对数据源的单词进行拆分,每个单词记为1,然后通过out.collect将数据发射到下游算子
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : value.split("\\s")) {
out.collect(new Tuple2<>(word, 1));
}
}
}
)
// 对单词进行分组
.keyBy(value -> value.f0)
// 对某个组里的单词的数量进行滚动相加统计
.reduce((a, b) -> new Tuple2<>(a.f0, a.f1 + b.f1));
// 4. 数据输出。字节输出到控制台
wordCountStream.print("WordCountStream=======").setParallelism(1);
// 5. 启动任务
env.execute(WordCountStream.class.getSimpleName());
}
原文链接: http://www.mangod.top/articles/2023/07/31/1690758123965.html、https://mp.weixin.qq.com/s/XICBfneJWFe4quwf3kRQXQ
感谢你的阅读,码字不易,欢迎点赞、关注、收藏!!!

标题:Flink DataStream API-概念、模式、作业流程和程序
作者:程序员半支烟
地址:http://mangod.top/articles/2023/07/31/1690758123965.html