 关于我
关于我
6个步骤搞定云原生应用监控和告警(建议收藏)
云原生系统搭建完毕之后,要建立可观测性和告警,有利于了解整个系统的运行状况。基于Prometheus搭建的云原生监控和告警是业内常用解决方案,每个云原生参与者都需要了解。
本文主要以springboot应用为例,讲解云原生应用监控和告警的实操,对于理论知识讲解不多。等朋友们把实操都理顺之后,再补充理论知识,就更容易理解整个体系了。
1、监控告警技术选型
kubernetes集群非常复杂,有容器基础资源指标、k8s集群Node指标、集群里的业务应用指标等等。面对大量需要监控的指标,传统监控方案Zabbix对于云原生监控的支持不是很好。
所以需要使用更适合云原生的监控告警方案prometheus,prometheus和云原生是密不可分的,并且prometheus现已成为云原生生态中监控的事实标准。下面来一步步搭建基于prometheus的监控告警方案。
prometheus的基本原理是:主动去**被监控的系统**拉取各项指标,然后汇总存入到自身的时序数据库,最后再通过图表展示出来,或者是根据告警规则触发告警。被监控的系统要主动暴露接口给prometheus去抓取指标。流程图如下:
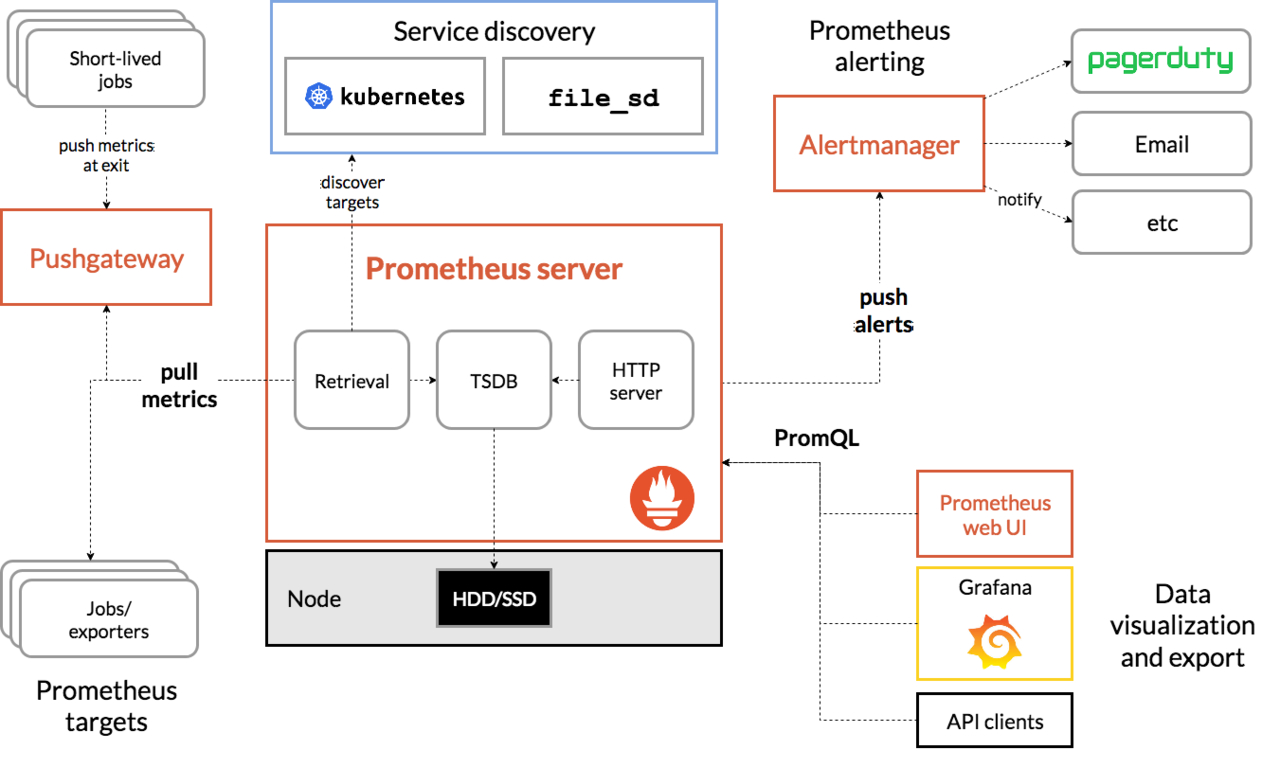
2、前置准备
本文的操作前提是:需要安装好docker、kubernetes,在K8S集群里部署好一个springboot应用。
假设K8S集群有4个节点,分别是:k8s-master(10.20.1.21)、k8s-worker-1(10.20.1.22)、k8s-worker-2(10.20.1.23)、k8s-worker-3(10.20.1.24)。
3、安装Prometheus
3.1、在k8s-master节点创建命名空间
kubectl create ns monitoring
3.2、准备configmap文件
准备configmap文件prometheus-config.yaml,yaml文件中暂时只配置了对于prometheus本身指标的抓取任务。下文会继续补充这个yaml文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
3.3、创建configmap
kubectl apply -f prometheus-config.yaml
3.4、准备prometheus的部署文件
准备prometheus的部署文件prometheus-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitoring
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
containers:
- image: prom/prometheus:v2.31.1
name: prometheus
securityContext:
runAsUser: 0
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus" # 指定tsdb数据路径
- "--storage.tsdb.retention.time=24h"
- "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
name: http
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
resources:
requests:
cpu: 200m
memory: 1024Mi
limits:
cpu: 200m
memory: 1024Mi
- image: jimmidyson/configmap-reload:v0.4.0 #prometheus配置动态加载
name: prometheus-reload
securityContext:
runAsUser: 0
args:
- "--volume-dir=/etc/config"
- "--webhook-url=http://localhost:9090/-/reload"
volumeMounts:
- mountPath: "/etc/config"
name: config-volume
resources:
requests:
cpu: 100m
memory: 50Mi
limits:
cpu: 100m
memory: 50Mi
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-data
- configMap:
name: prometheus-config
name: config-volume
3.5、准备prometheus的存储文件
准备prometheus的存储文件prometheus-storage.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-local
labels:
app: prometheus
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
storageClassName: local-storage
local:
path: /data/k8s/prometheus #确保该节点上存在此目录
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-worker-2
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data
namespace: monitoring
spec:
selector:
matchLabels:
app: prometheus
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: local-storage
这里我使用的是k8s-worker-2节点作为存储资源,读者们使用时要改成自己的节点名称,同时要在对应的节点下创建目录:/data/k8s/prometheus。最终时序数据库的数据会存储到此目录下,见下图:
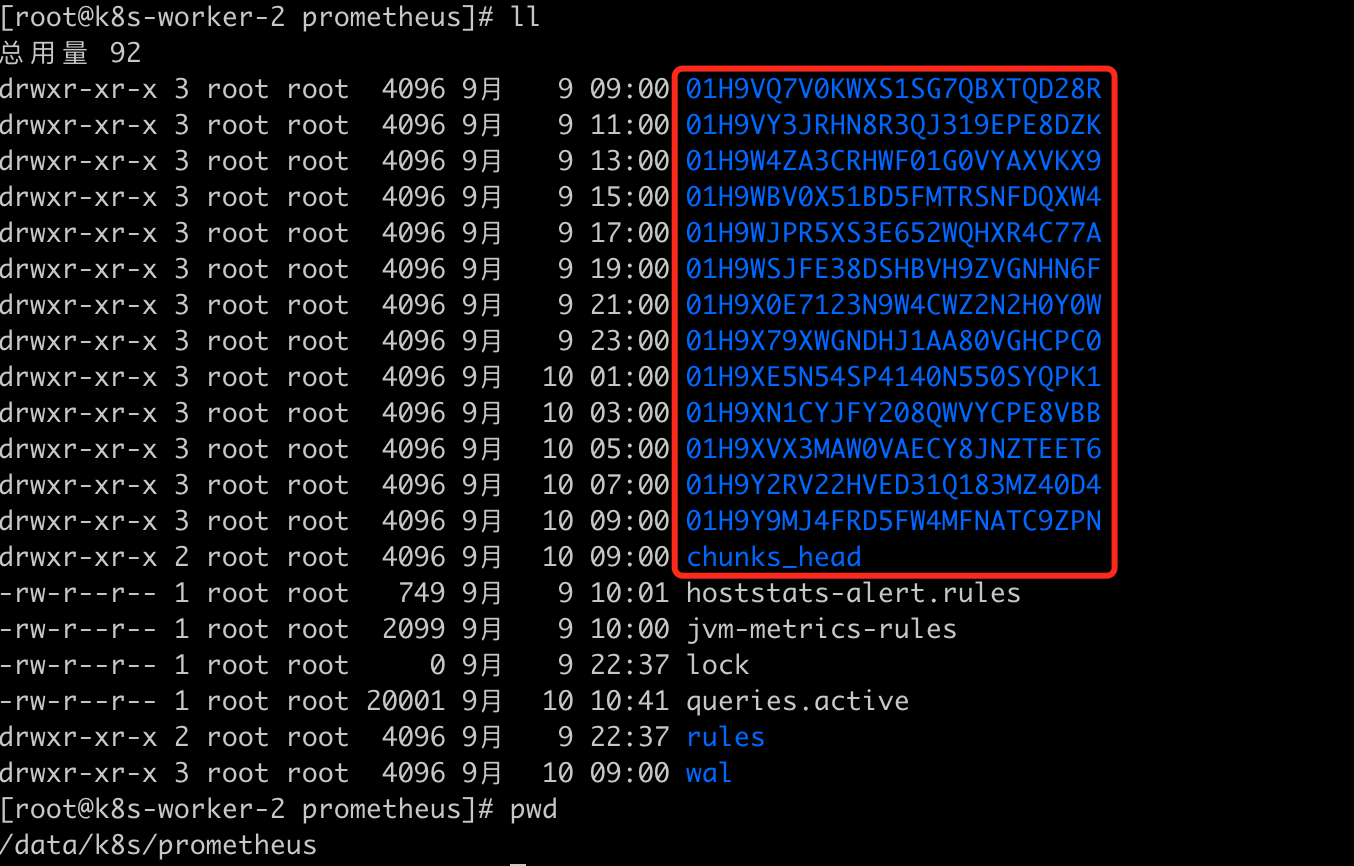
上面的yaml中用到了pv、pvc、storageclass存储相关的知识,后面写篇文章讲解下,这里简单介绍下:pv、pvc、storageclass主要是为pod自动创建存储资源相关的组件。
3.6、创建存储资源
kubectl apply -f prometheus-storage.yaml
3.7、准备用户、角色、权限相关文件
准备用户、角色、权限相关文件prometheus-rbac.yaml:
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring
3.8、创建RBAC资源
kubectl apply -f prometheus-rbac.yaml
3.9、创建deployment资源
kubectl apply -f prometheus-deploy.yaml
3.10、准备service资源对象文件
准备service资源对象文件prometheus-svc.yaml。采用NortPort方式,供外部访问prometheus:
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitoring
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http
3.11、创建service对象:
kubectl apply -f prometheus-svc.yaml
3.12、访问prometheus
此时通过kubectl get svc -n monitoring获取暴露的端口号,通过K8S集群的任意节点+端口号就可以访问prometheus了。比如通过http://10.20.1.21:32459/访问,可以看到如下界面,通过targets可以看到上面prometheus-config.yaml文件中配置的被抓取对象:

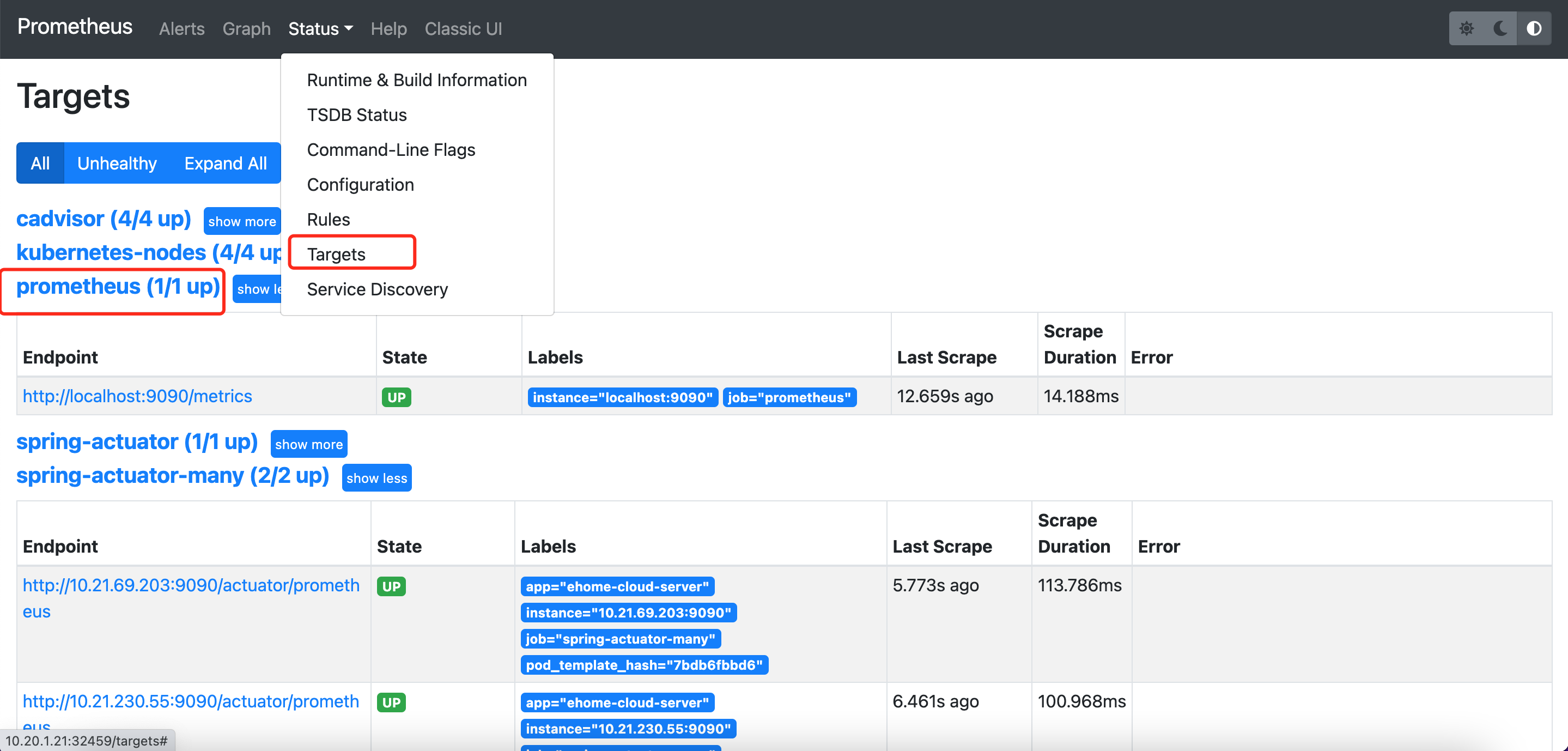
至此prometheus安装完毕,下面继续安装grafana。
4、安装Grafana
prometheus的图表功能比较弱,一般使用grafana来展示prometheus的数据,下面开始安装grafana。
4.1、准备grafana部署文件
准备grafana部署文件grafana-deploy.yaml,这是一个all-in-one的文件,将Deployment、Service、PV、PVC的编排全部写在该文件中:
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: monitoring
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana-data
containers:
- name: grafana
image: grafana/grafana:8.3.3
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 0
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 400m
memory: 1024Mi
requests:
cpu: 200m
memory: 512Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: storage
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-local
labels:
app: grafana
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 1Gi
storageClassName: local-storage
local:
path: /data/k8s/grafana #保证节点上创建好该目录
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-worker-2
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-data
namespace: monitoring
spec:
selector:
matchLabels:
app: grafana
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: local-storage
上文中依旧用到了PV、PVC、StorageClass的知识,节点亲和选择了k8s-worker-2节点,同时需要在该节点上创建改目录/data/k8s/grafana。
4.2、部署grafana资源
kubectl apply -f grafana-deploy.yaml
4.3、访问grafana
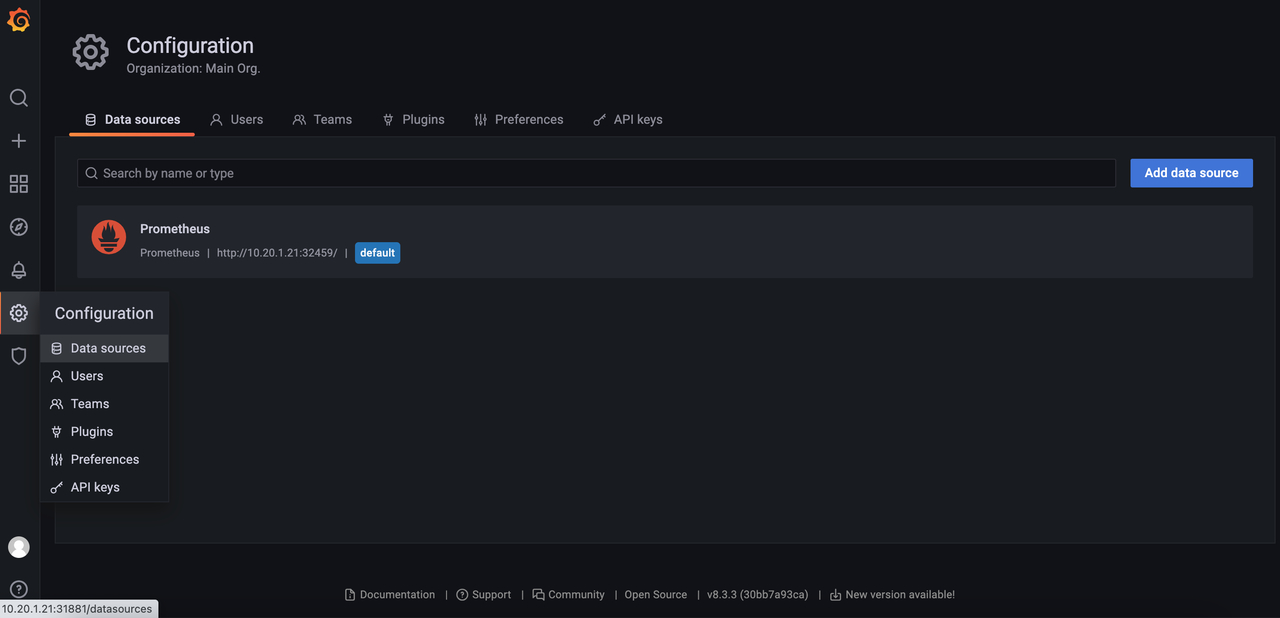
查看对应的service端口映射:

通过链接http://10.20.1.21:31881/访问grafana,通过配置文件中的用户名和密码访问grafana,再导入prometheus的数据源:
5、配置数据抓取
5.1、配置抓取node数据
在抓取数据之前,需要在node节点上配置node-exporter,这样prometheus才能通过node-exporter暴露的接口抓取数据。
5.1.1、准备node-exporter的部署文件
准备node-exporter的部署文件node-exporter-daemonset.yaml:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-system
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: prom/node-exporter:v1.3.1
args:
- --web.listen-address=$(HOSTIP):9100
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --no-collector.hwmon # 禁用不需要的一些采集器
- --no-collector.nfs
- --no-collector.nfsd
- --no-collector.nvme
- --no-collector.dmi
- --no-collector.arp
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)
- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9100
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 200Mi
limits:
cpu: 300m
memory: 400Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
tolerations: # 添加容忍
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
5.1.2、部署node-exporter
kubectl apply -f node-exporter-daemonset.yaml
5.1.3、prometheus接入抓取数据
在之前的prometheus-config.yaml文件中继续增加job-name,如下:
- job_name: kubernetes-nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
完整的prometheus-config.yaml见文末。
prometheus-config.yaml文件修改完,稍等一会儿就可以看到页面多了几个target,如下图所示,这些都是被prometheus监控的对象:
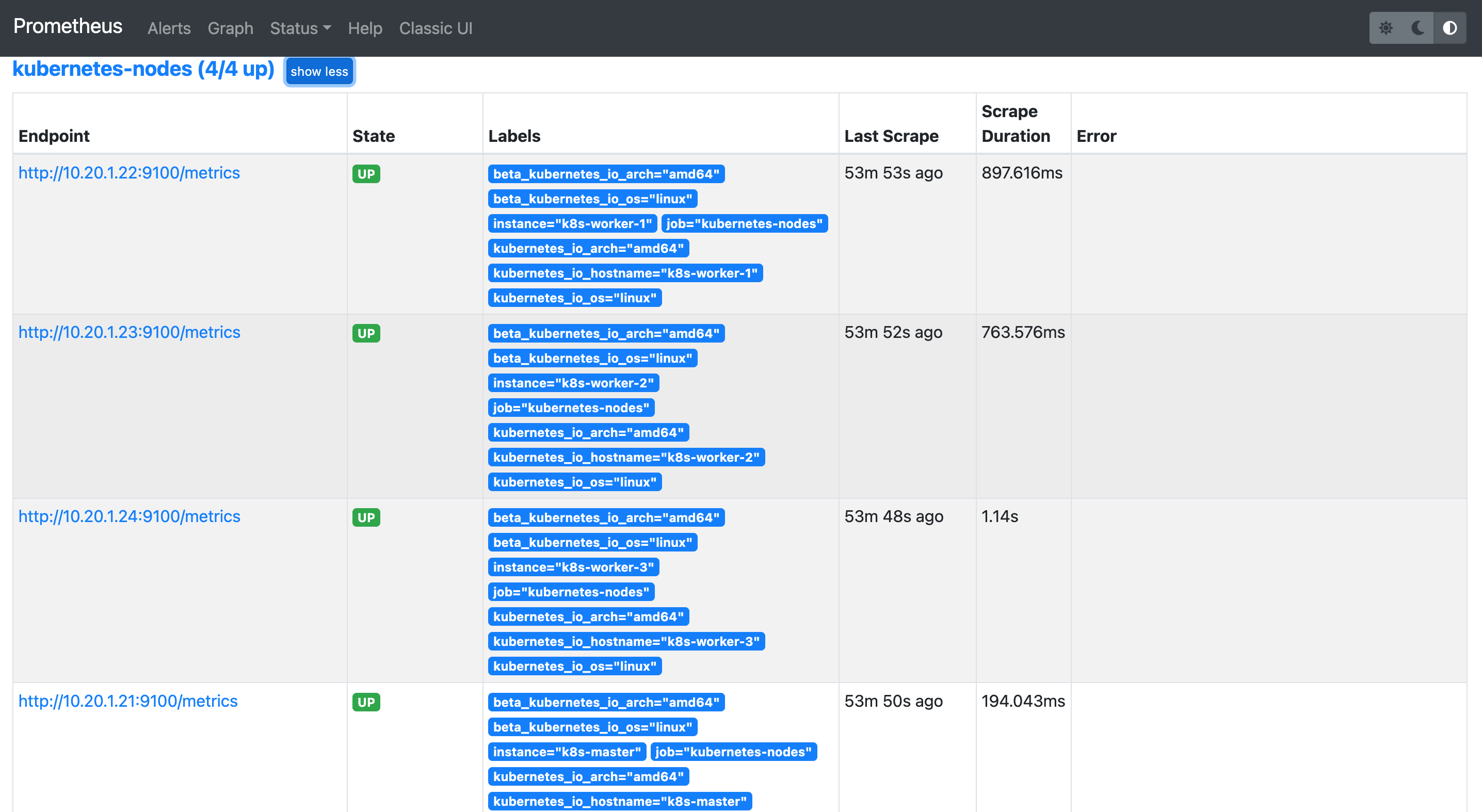
5.2、配置抓取springboot actuator数据
5.2.1、配置springboot应用
- springboot应用增加pom
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
- springboot应用配置properties文件:
management.endpoint.health.probes.enabled=true
management.health.probes.enabled=true
management.endpoint.health.enabled=true
management.endpoint.health.show-details=always
management.endpoints.web.exposure.include=*
management.endpoints.web.exposure.exclude=env,beans
management.endpoint.shutdown.enabled=true
management.server.port=9090
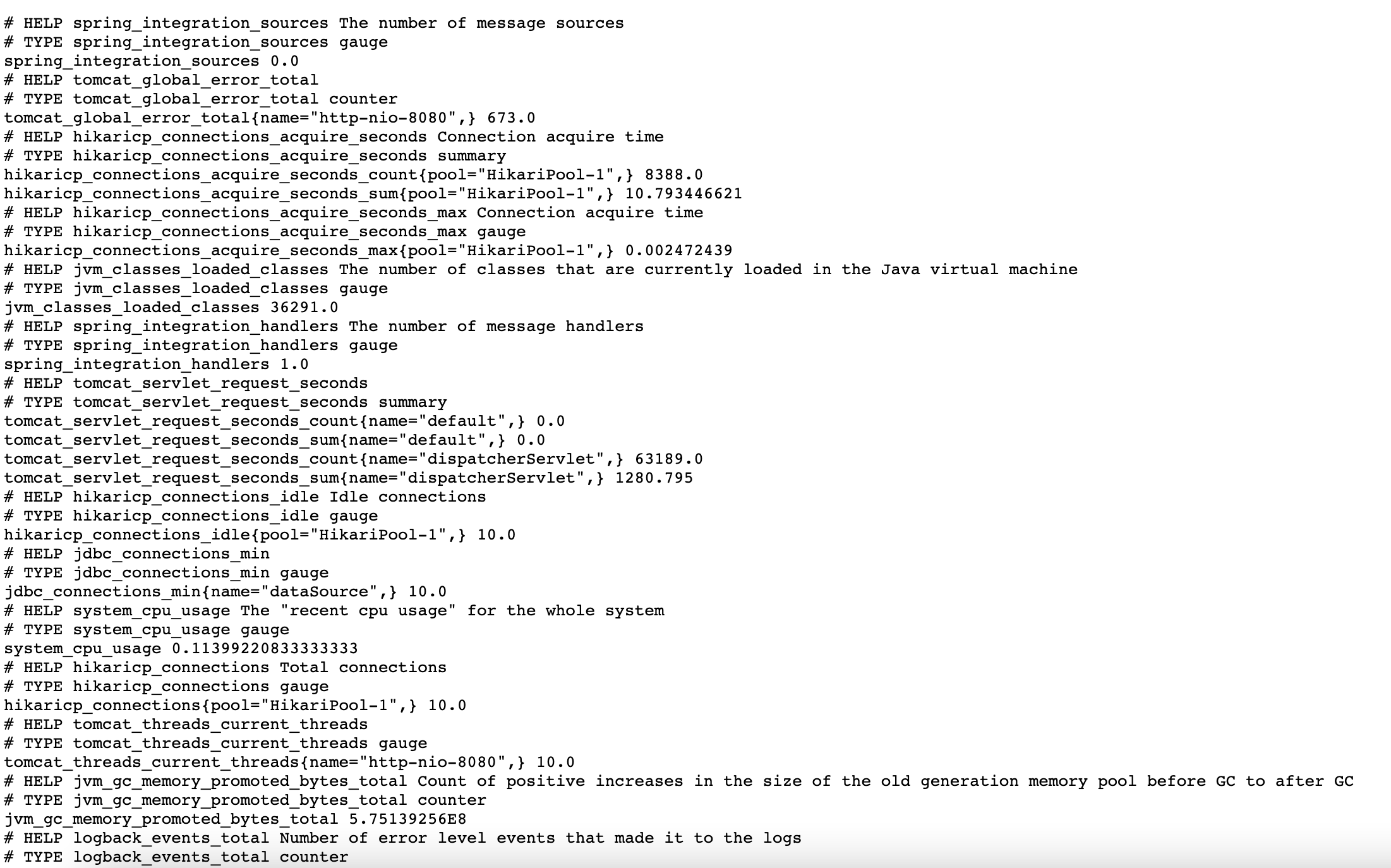
- 查看指标链接
配置完之后,重新打镜像部署到K8S集群,这里不做演示了。访问应用的/actuator/prometheus链接得到如下结果,将系统的指标信息暴露出来:
5.2.2、prometheus接入抓取数据
继续修改配置文件prometheus-config.yaml,如下:
- job_name: 'spring-actuator-many'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: 'test1'
target_label: namespace
action: keep
- source_labels: [__address__]
regex: '(.*):9090'
target_label: __address__
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
配置文件中的大概意思是,选择“端口是9090,namespace是test1”的pod资源进行监控。更多的语法,读者自行查阅prometheus官网。
稍等片刻,可以看到多了springboot应用的监控目标:
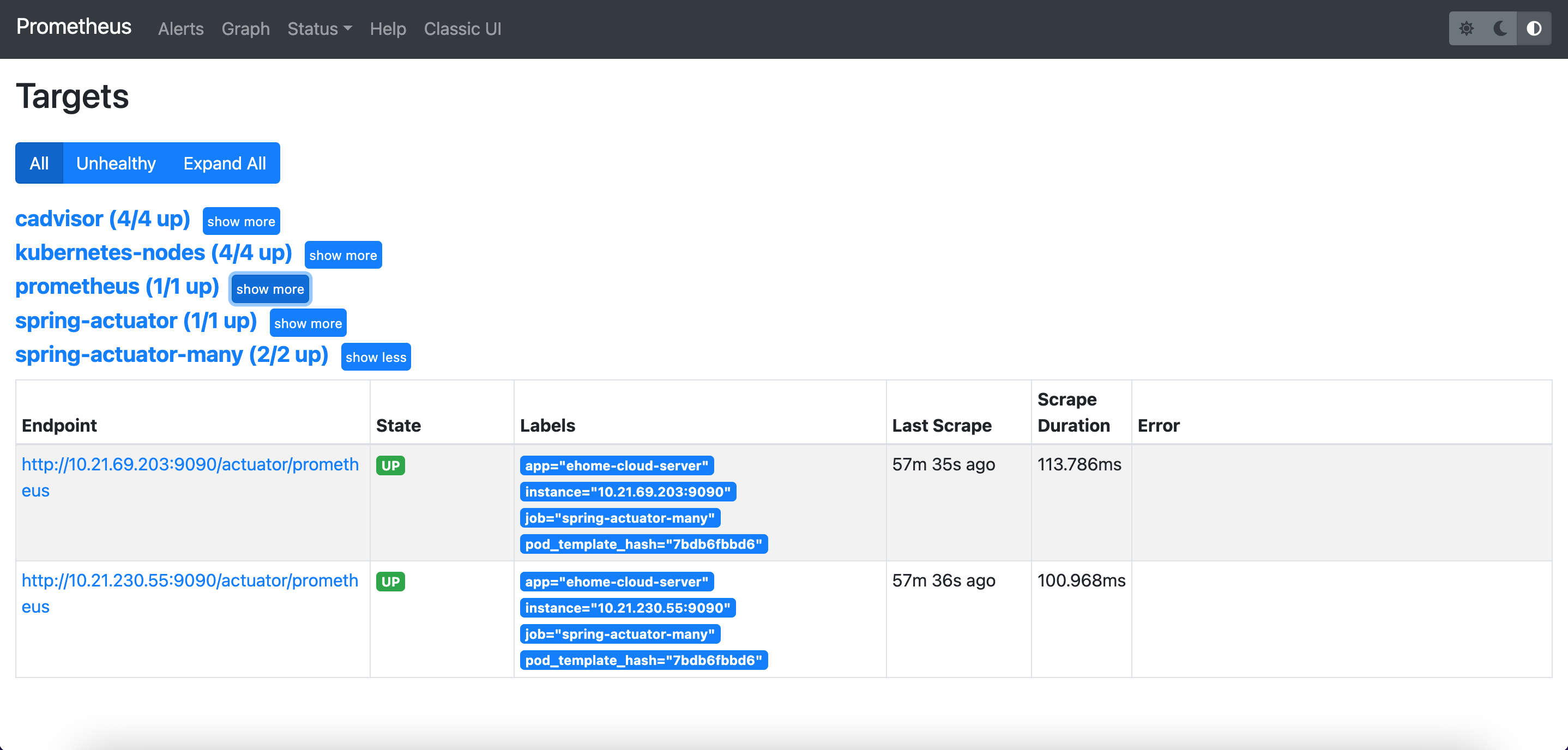
6、配置监控图表
指标数据都有了,接下来就是如何配置图表了。grafana提供了丰富的图表,可以在官网上自行选择。下文继续配置监控node的图表 和 监控springboot应用的图表。
配置图表有3种方式:json文件、输入图表id、输入json内容。配置界面如下图:
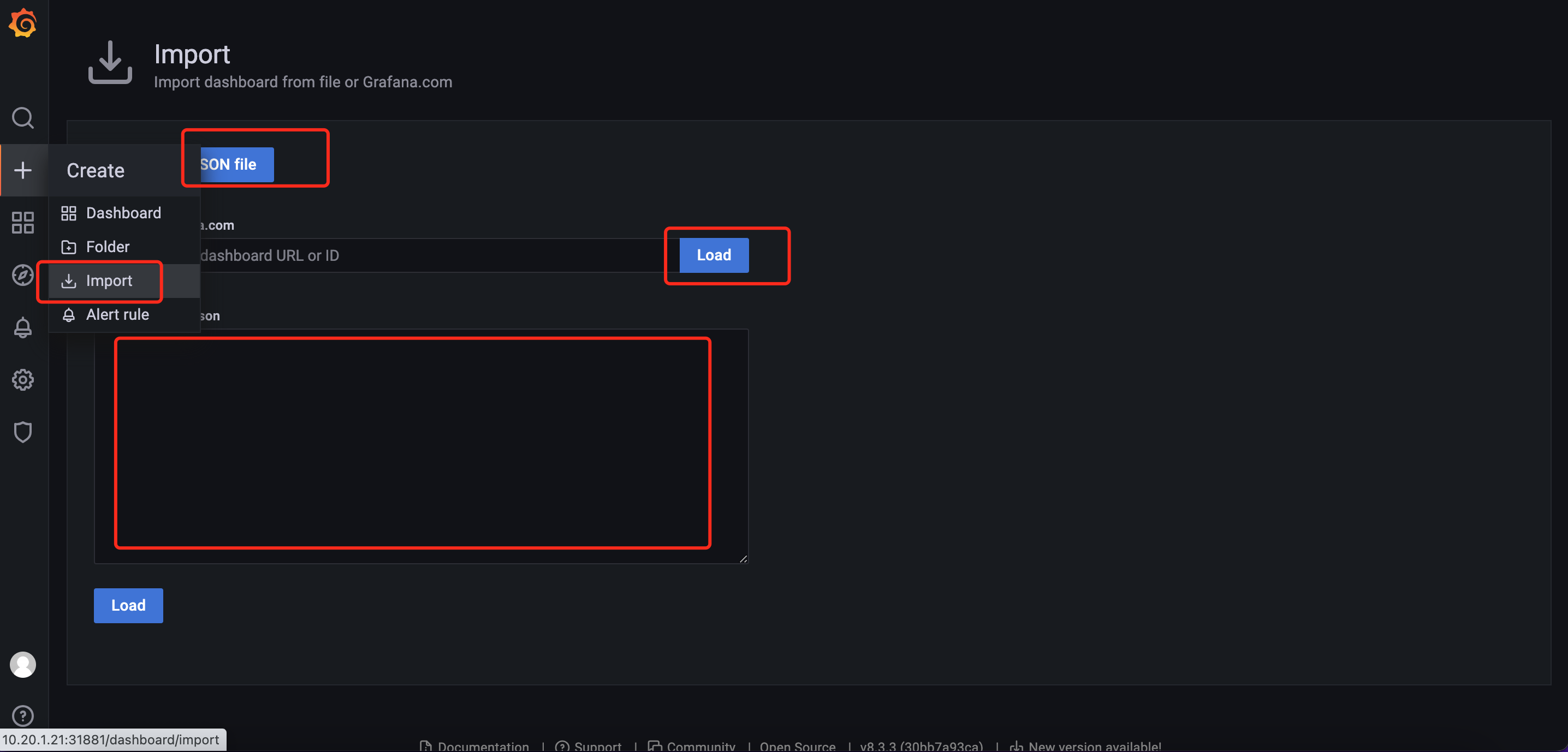
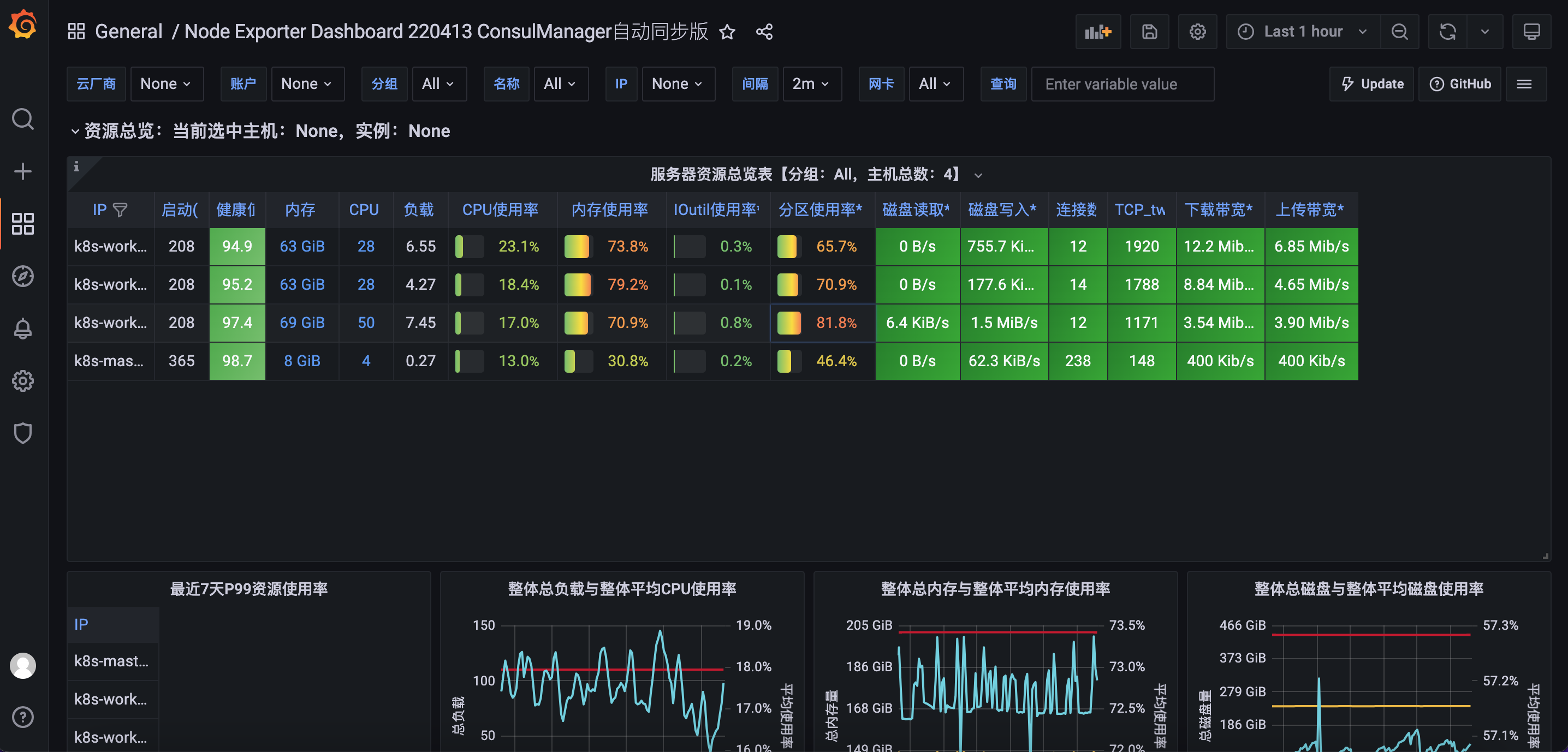
6.1、配置node监控图表
在上图的界面中选择输入图表id的方式,输入图表id8919,即可看到如下界面:
6.2、配置springboot应用的图表
在上图的界面中选择输入json内容的方式,输入此链接下的json内容https://img.mangod.top/blog/jvm-micrometer.json,即可看到如下图表:
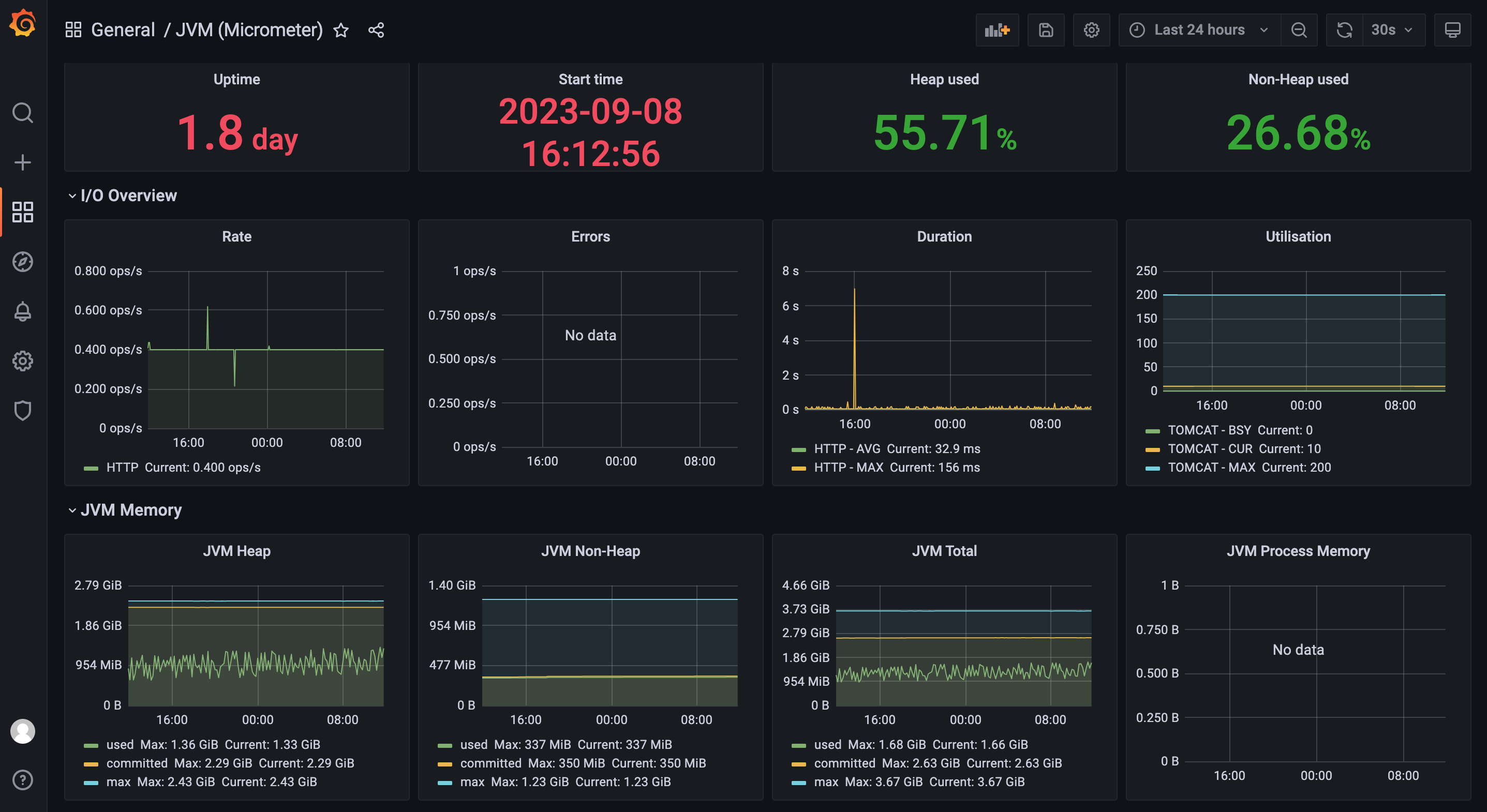
至此k8s-node监控和springboot应用监控已经完成。如果还需要更多的监控,读者需要自行查阅资料。
7、安装告警alertmanager
监控完成之后,就是安装告警组件alertmanager了。可以选择在K8S集群下的任一节点使用docker安装。
7.1、安装alertmanager
7.1.1、拉取docker镜像
docker pull prom/alertmanager:v0.25.0
7.1.2、创建报警配置文件
创建报警配置文件alertmanager.yml之前,需要在安装alertmanager所在节点上创建目录/data/prometheus/alertmanager,在目录下创建文件alertmanager.yml,内容如下:
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'mail_163'
global:
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '294931067@qq.com'
smtp_auth_username: '294931067@qq.com'
# 此处是发送邮件的授权码,不是密码
smtp_auth_password: '此处是授权码,比如sdfasdfsdffsfa'
smtp_require_tls: false
receivers:
- name: 'mail_163'
email_configs:
- to: 'yclxiao@163.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
7.1.3、安装启动:
docker run --name alertmanager -d -p 9093:9093 -v /data/prometheus/alertmanager:/etc/alertmanager prom/alertmanager:v0.25.0
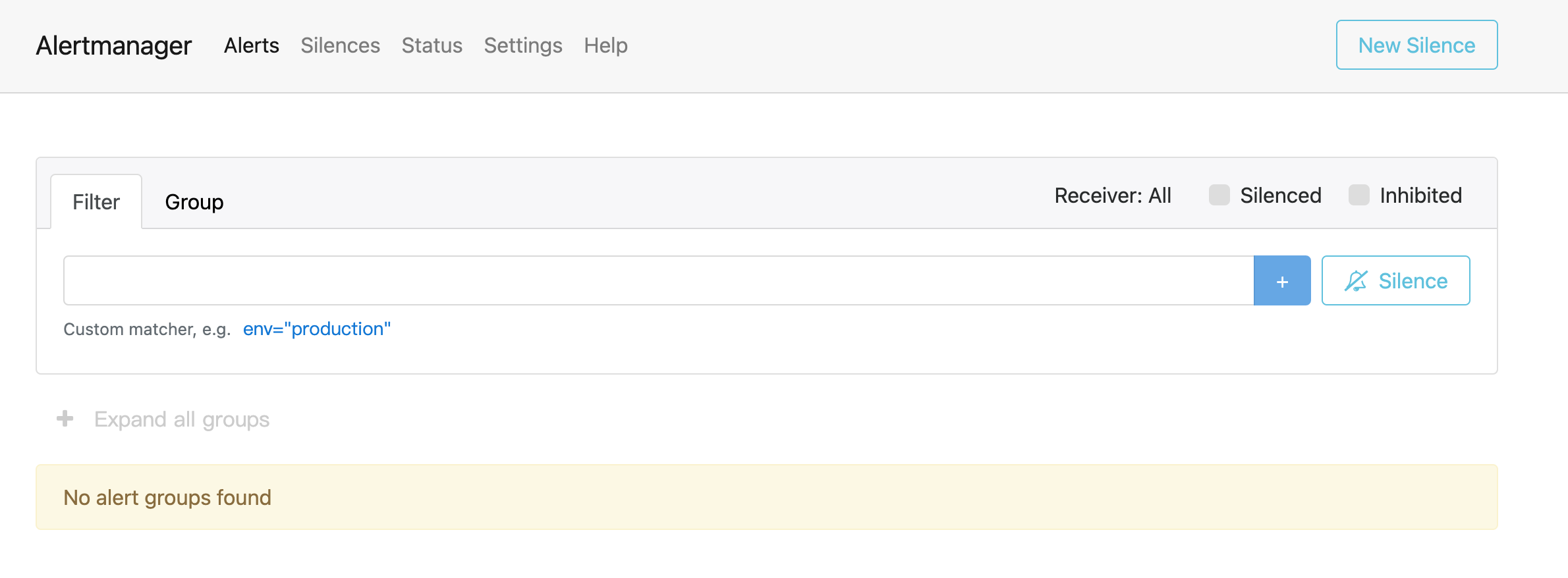
7.1.4、访问alertmanager
安装完毕之后,通过如下链接访问:http://10.20.1.21:9093/#/alerts,界面如下:
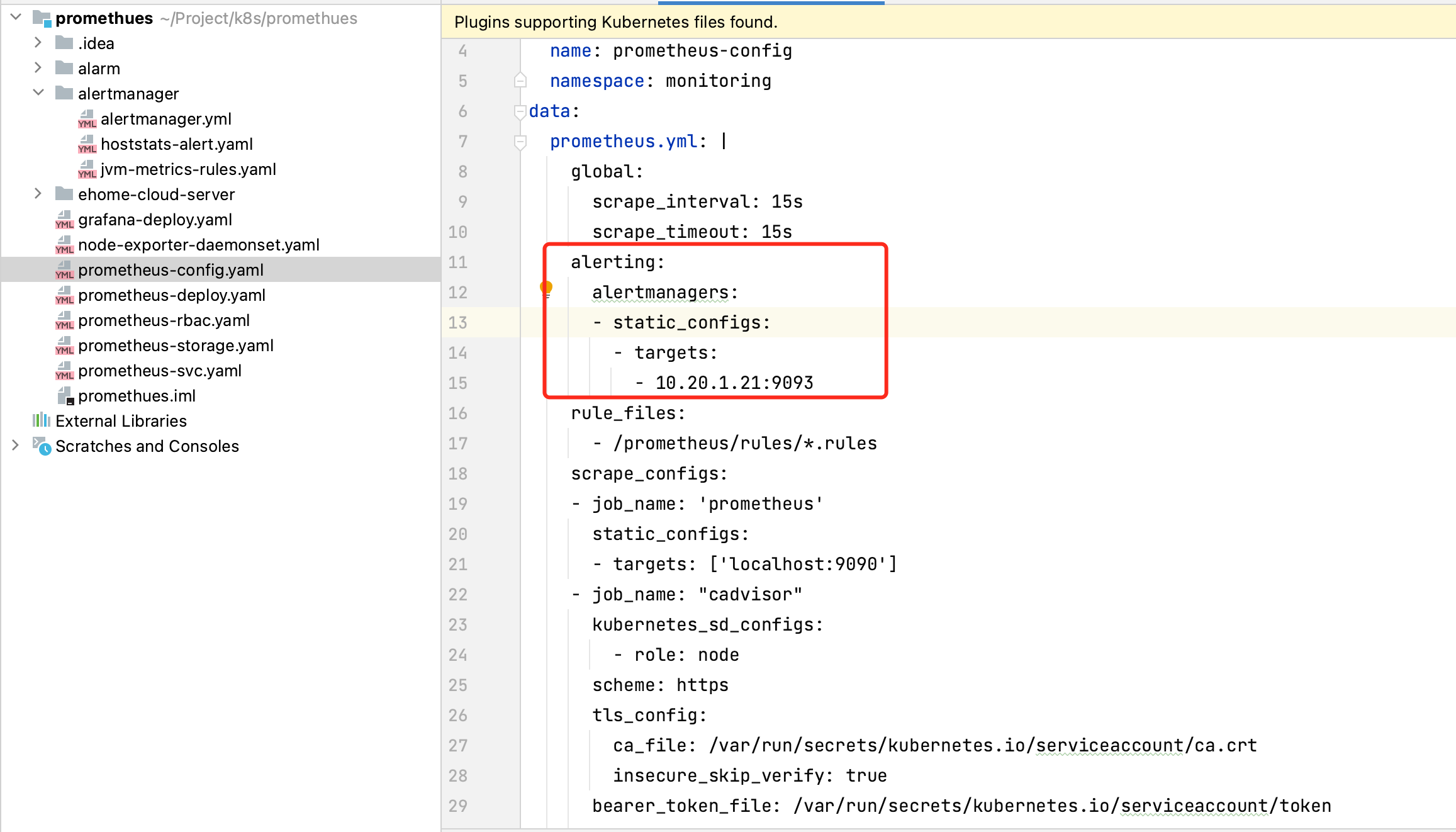
7.2、与prometheus关联
在prometheus-configmap.yaml文件中增加如下配置,即可让prometheus与alertmanager关联起来,配置中的地址改成自己的prometheus地址。
7.3、配置触发告警规则
7.3.1、增加配置目录
在prometheus-configmap.yaml文件中增加如下配置,即可增加触发告警的规则:
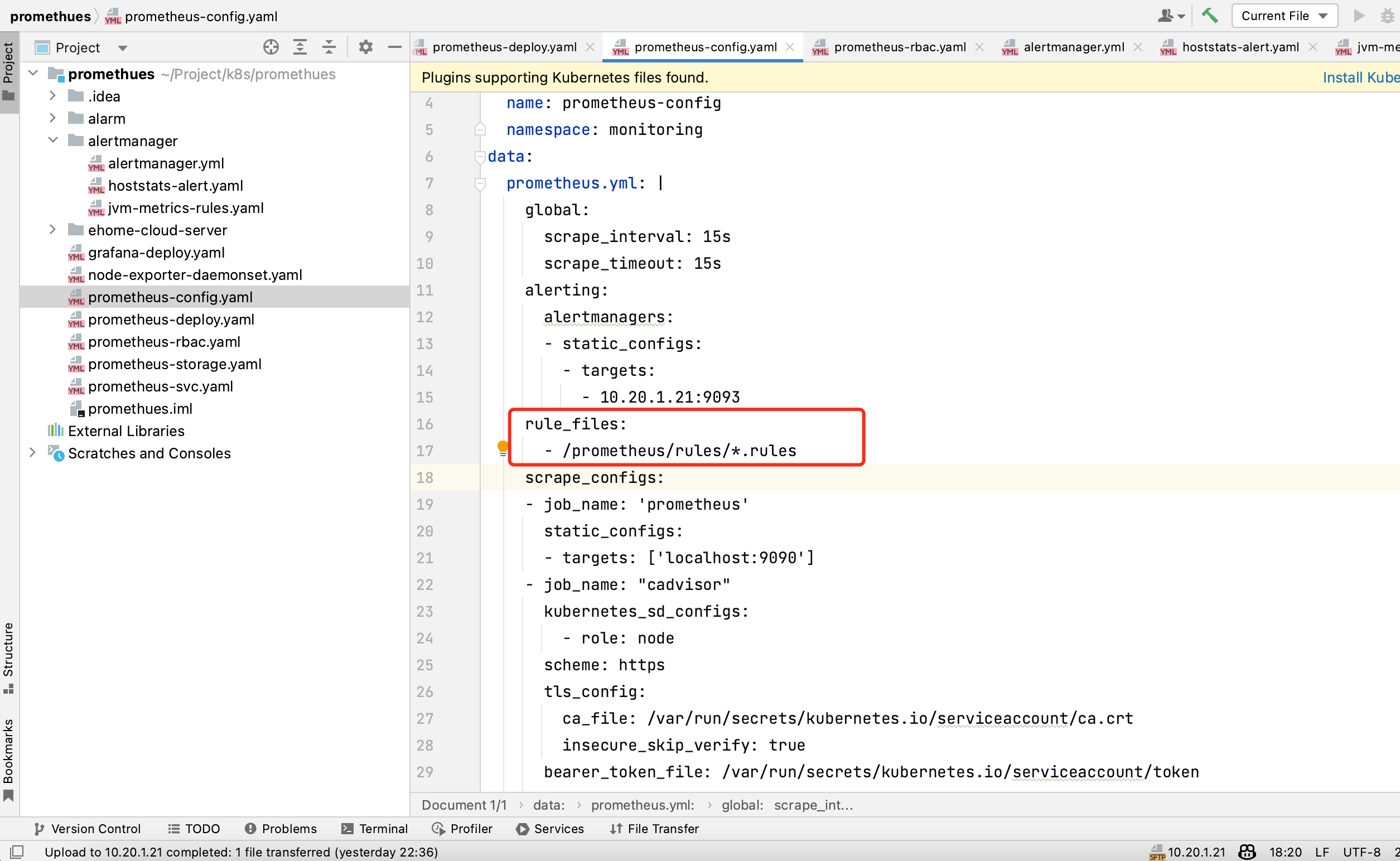
注意此处的文件目录/prometheus/是prometheus所在存储目录,我这里是安装在k8s-worker-2下,然后在prometheus的存储目录下建立/rules文件夹,如下图:

至此prometheus-config.yaml全部配置完毕,最后附上完整的prometheus-config.yaml:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.20.1.21:9093
rule_files:
- /prometheus/rules/*.rules
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: "cadvisor"
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
- replacement: /metrics/cadvisor # <nodeip>/metrics -> <nodeip>/metrics/cadvisor
target_label: __metrics_path__
- job_name: kubernetes-nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'spring-actuator-many'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: 'test1'
target_label: namespace
action: keep
- source_labels: [__address__]
regex: '(.*):9090'
target_label: __address__
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
7.3.2、配置触发告警规则
触发告警规则的目录已经定好了,接下来就是写具体规则了,在目录下创建2个触发告警的规则文件,如上图,文件中写了触发node节点告警规则和触发springboot应用的告警规则,具体内容如下:
- node节点告警规则-
hoststats-alert.yaml:
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance) > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
- springboot应用告警规则-
jvm-metrics-rules.yaml:
groups:
- name: jvm-metrics-rules
rules:
# 在5分钟里,GC花费时间超过10%
- alert: GcTimeTooMuch
expr: increase(jvm_gc_collection_seconds_sum[5m]) > 30
for: 5m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} GC时间占比超过10%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} GC时间占比超过10%,当前值({{ $value }}%)"
# GC次数太多
- alert: GcCountTooMuch
expr: increase(jvm_gc_collection_seconds_count[1m]) > 30
for: 1m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} 1分钟GC次数>30次"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} 1分钟GC次数>30次,当前值({{ $value }})"
# FGC次数太多
- alert: FgcCountTooMuch
expr: increase(jvm_gc_collection_seconds_count{gc="ConcurrentMarkSweep"}[1h]) > 3
for: 1m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} 1小时的FGC次数>3次"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} 1小时的FGC次数>3次,当前值({{ $value }})"
# 非堆内存使用超过80%
- alert: NonheapUsageTooMuch
expr: jvm_memory_bytes_used{job="spring-actuator-many", area="nonheap"} / jvm_memory_bytes_max * 100 > 80
for: 1m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} 非堆内存使用>80%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} 非堆内存使用率>80%,当前值({{ $value }}%)"
# 内存使用预警
- alert: HeighMemUsage
expr: process_resident_memory_bytes{job="spring-actuator-many"} / os_total_physical_memory_bytes * 100 > 15
for: 1m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} rss内存使用率大于85%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} rss内存使用率大于85%,当前值({{ $value }}%)"
# JVM高内存使用预警
- alert: JavaHeighMemUsage
expr: sum(jvm_memory_used_bytes{area="heap",job="spring-actuator-many"}) by(app,instance) / sum(jvm_memory_max_bytes{area="heap",job="spring-actuator-many"}) by(app,instance) * 100 > 85
for: 1m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} rss内存使用率大于85%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} rss内存使用率大于85%,当前值({{ $value }}%)"
# CPU使用预警
- alert: JavaHeighCpuUsage
expr: system_cpu_usage{job="spring-actuator-many"} * 100 > 85
for: 1m
labels:
severity: red
annotations:
summary: "{{ $labels.app }} rss CPU使用率大于85%"
message: "ns:{{ $labels.namespace }} pod:{{ $labels.pod }} rss内存使用率大于85%,当前值({{ $value }}%)"
- 告警文件准备好之后,先重启alertmanager,再重启prometheus:

kubectl delete -f prometheus-deploy.yaml
kubectl apply -f prometheus-deploy.yaml
- 查看界面
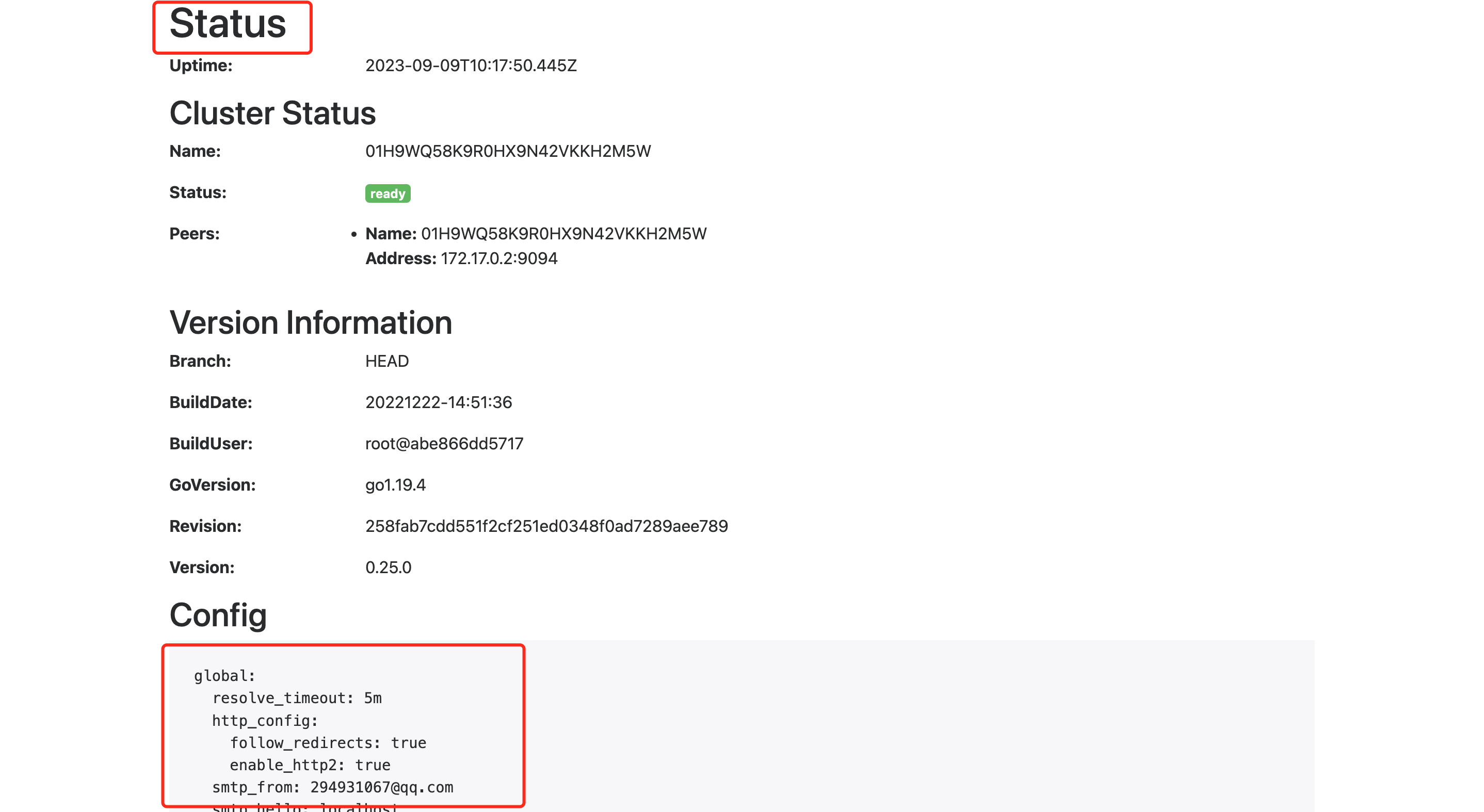
此时查看alertmanager的status,可以看到如下界面:
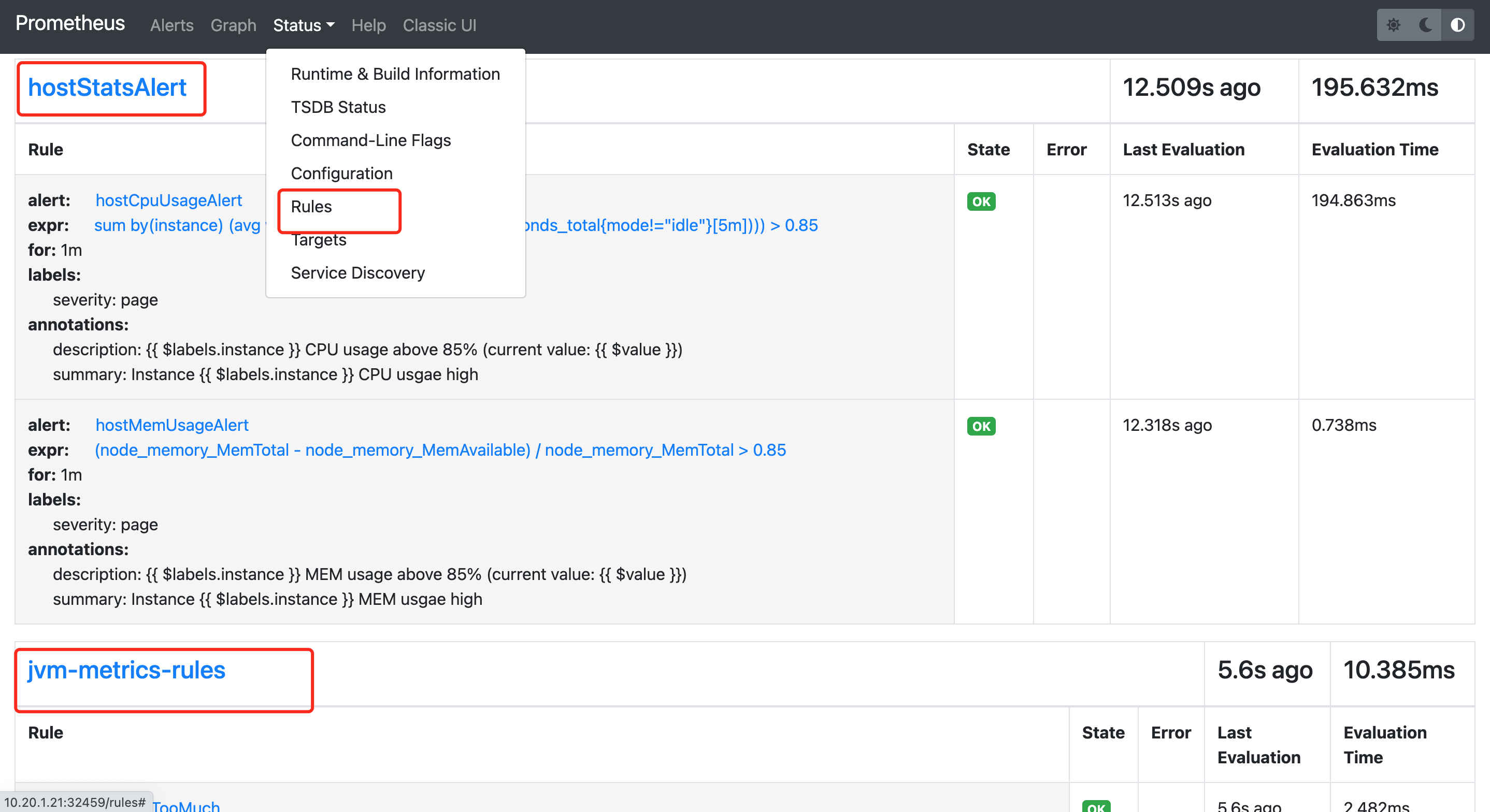
此时查看promethetus的rules,可以看到如下界面:
7.3.3、注意点
- 改了alertmanager的告警配置要重启alertmanager才生效。
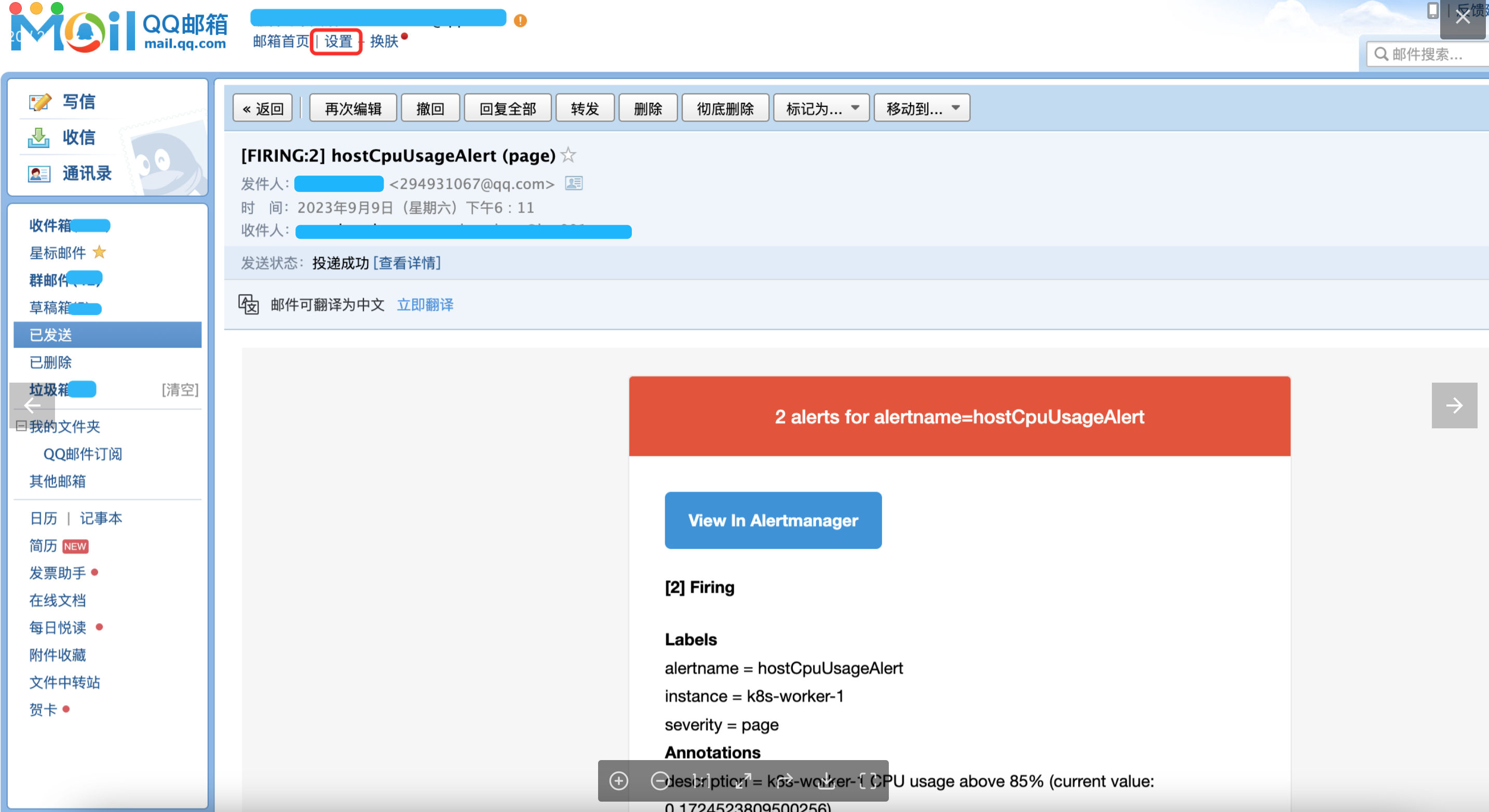
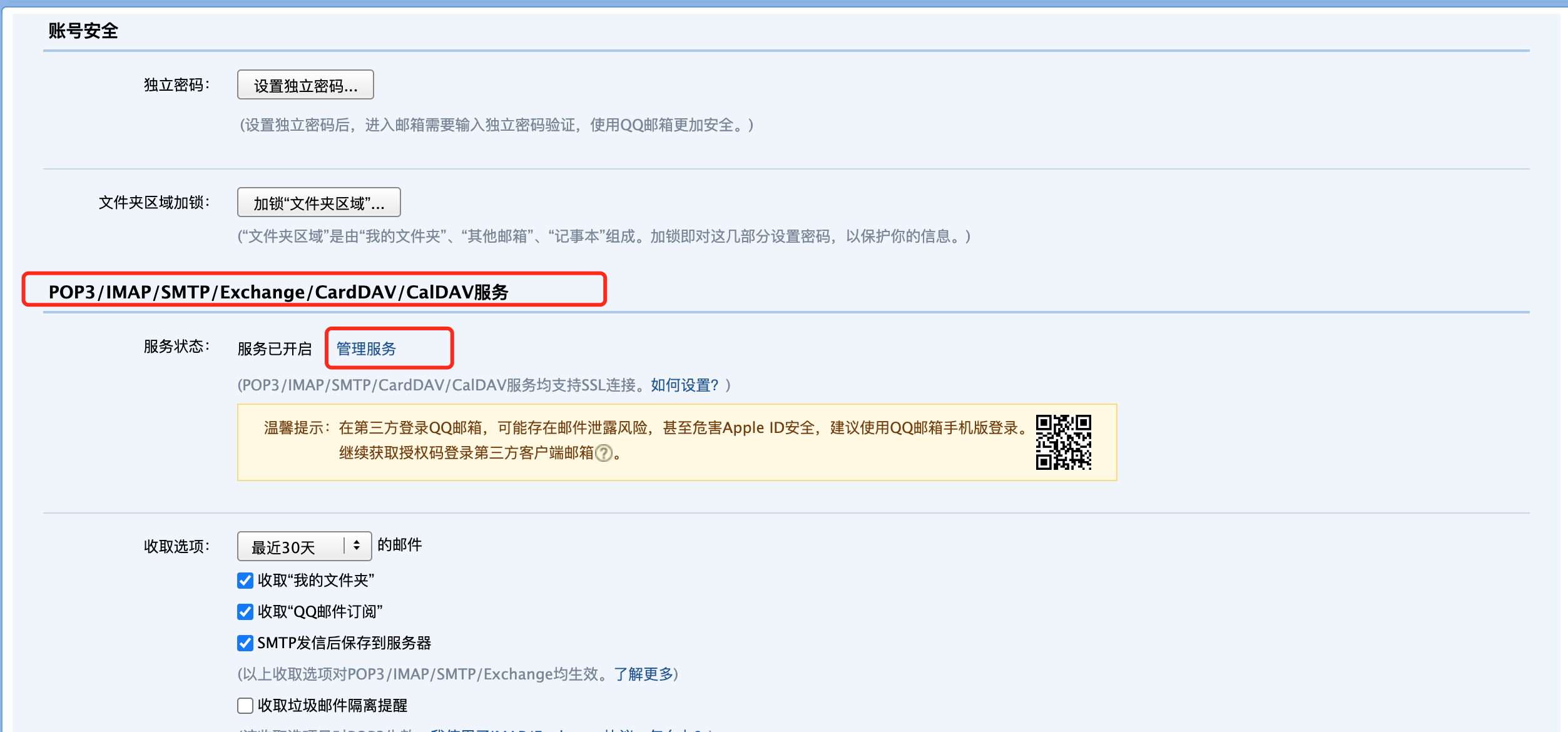
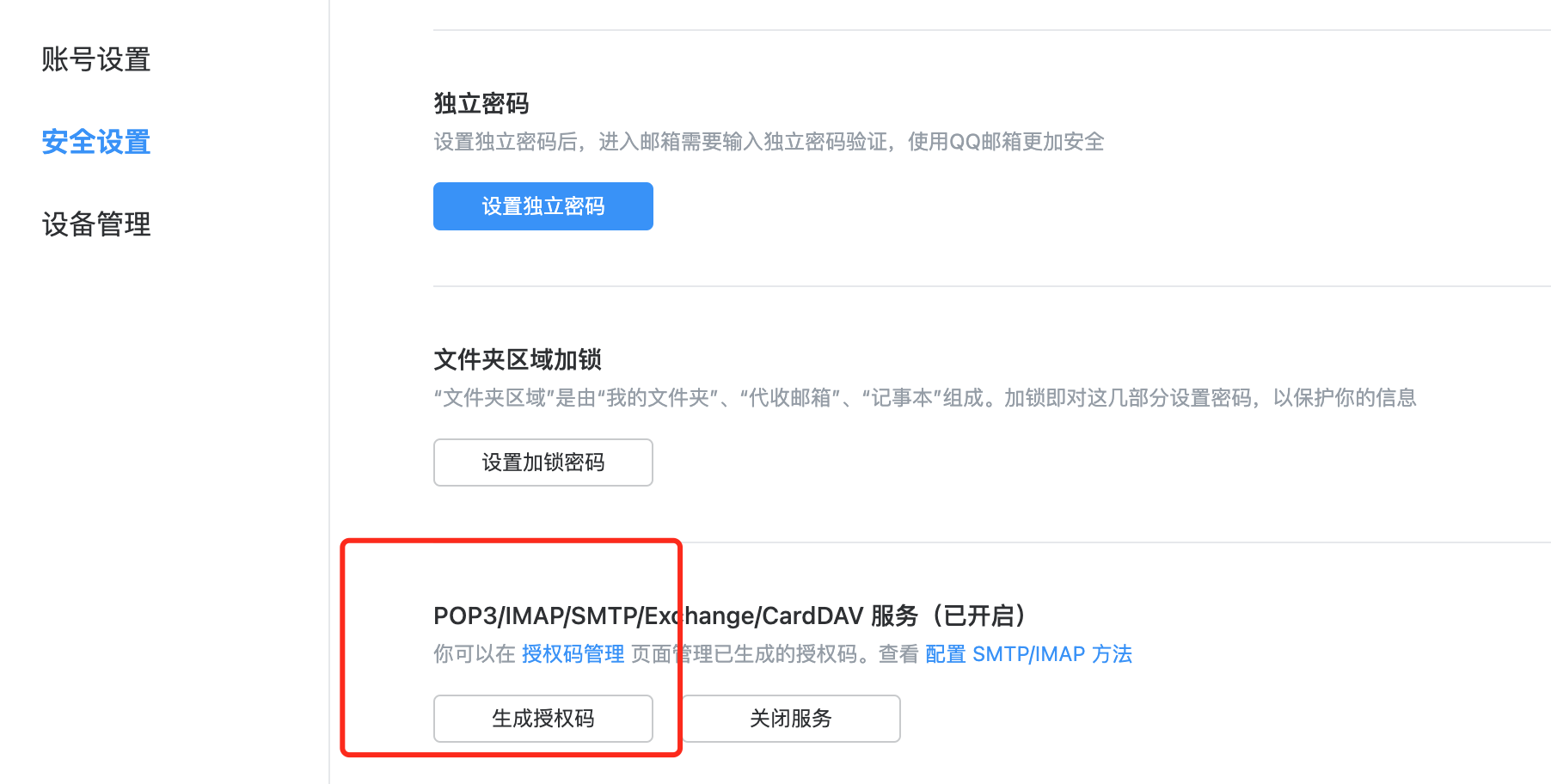
alertmanager.yml中的smtp_auth_password配置的是邮件发送的授权码,不是邮箱密码。邮箱的授权码的配置如下图,下图以QQ邮箱为例:
至此基于Prometheus和Grafana的监控和告警已经安装完毕。
8、测试告警
安装完毕后,简单测试下告警效果。有2种方式测试。
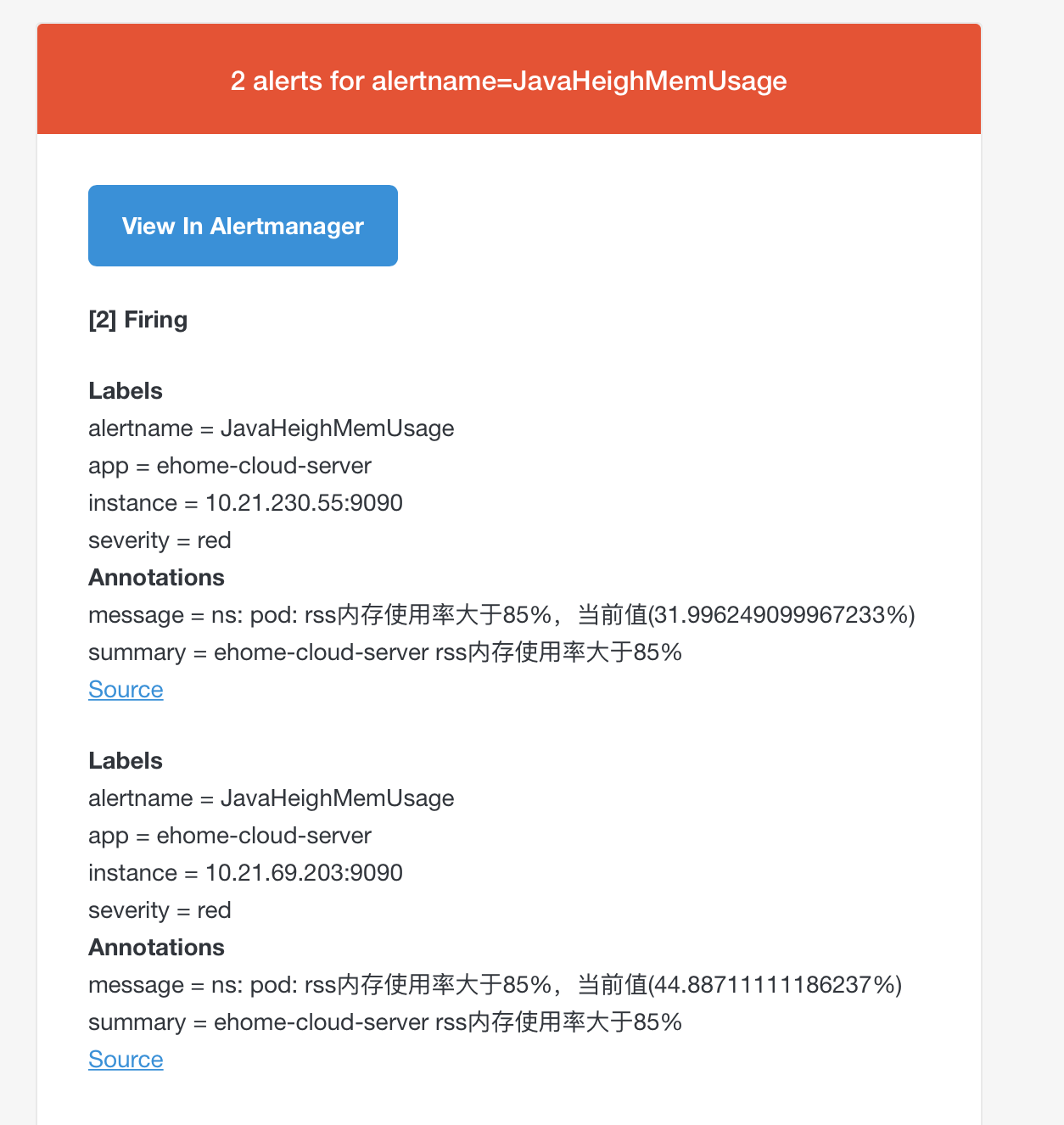
- 方式1:将告警规则值调低,会收到如下邮件:
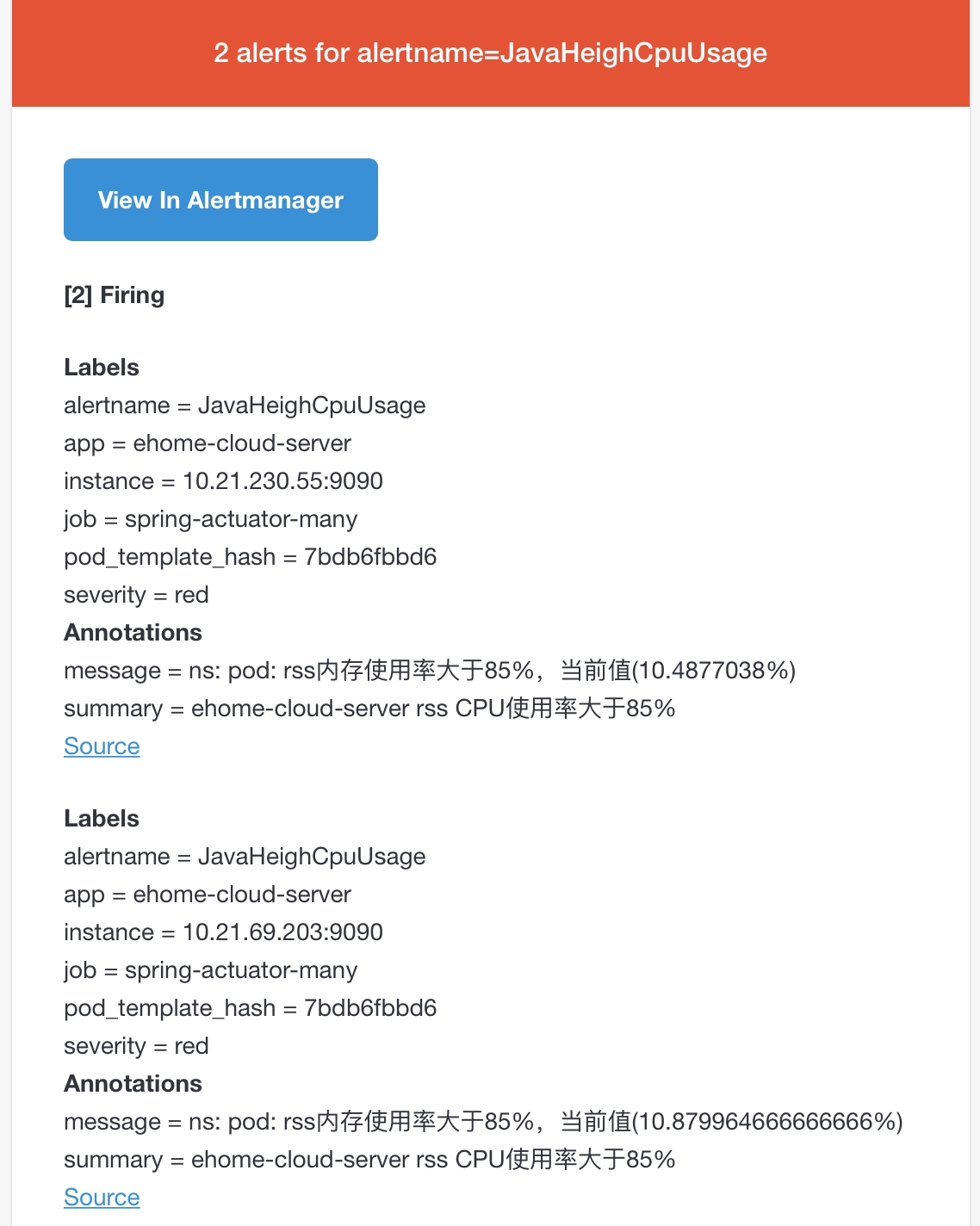
- 方式2:通过命令
cat /dev/zero>/dev/null拉高node节点的cpu或者拉高容器的cpu,,会收到如下邮件:
9、总结
本文主要讲解基于Prometheus + Grafana的云原生应用监控和告警的实战,助你快速搭建系统,希望对你有帮助!
本篇完结!感谢你的阅读,欢迎点赞 关注 收藏 私信!!!
原文链接: http://www.mangod.top/articles/2023/09/10/1694336145377.html、https://mp.weixin.qq.com/s/bxRdOavM2BZEovEnoZ6wZw
