 关于我
关于我
Flink DataStream API-数据源、数据转换、数据输出
本文继续介绍Flink DataStream API先关内容,重点:数据源、数据转换、数据输出。
1、Source数据源
1.1、Flink基本数据源
- 文件数据源
// 2. 读取数据源
DataStream<String> fileDataStreamSource =
env.readTextFile("/Users/yclxiao/Project/bigdata/flink-blog/doc/words.txt");
- Socket数据源
// 2. 读取数据源
DataStream<String> textStream = env.socketTextStream("localhost", 9999, "\n");
- 集合数据源
DataStreamSource<String> textStream = env.fromCollection(Arrays.asList(
"java,c++,php,java,spring",
"hadoop,scala",
"c++,jvm,html,php"
));
1.2、高级数据源
Flink可以从Kafka、Mysql-CDC等数据源读取数据,使用时需要引入第三方依赖库。
对接Kafka数据源 :
在Maven中引入Flink针对Kafka的API依赖库,pom代码如下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
Java代码如下:
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据源
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("10.20.1.26:9092")
.setGroupId("group-flinkdemo")
.setTopics("topic-flinkdemo")
// 从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest())
// 从上次消费者提交的地方开始消费,应该采用这种方式,防止服务重启的期间丢失数据
// .setStartingOffsets(OffsetsInitializer.committedOffsets())
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class))
.build();
DataStreamSource<String> dataStreamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "KafkaSource");
// 3. 数据转换
DataStream<Tuple2<String, Integer>> dataStream = dataStreamSource
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : value.split("\\,")) {
out.collect(new Tuple2<>(word, 1));
}
}
})
.keyBy(value -> value.f0)
.reduce((a, b) -> new Tuple2<>(a.f0, a.f1 + b.f1));
dataStream.print("BlogDemoStream=======")
.setParallelism(1);
// 5. 启动任务
env.execute(KafkaDataStreamSourceDemo.class.getSimpleName());
简单的小视频如下:
https://img.mangod.top/blog/202308031448483.mp4
对接Myql-CDC数据源
详细的过程可以查看我的这边文章:一次打通FlinkCDC同步Mysql数据,
在Maven中引入Flink针对Mysql-CDC的API依赖库,pom代码如下:
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.3.0</version>
<exclusions>
<exclusion>
<artifactId>flink-shaded-guava</artifactId>
<groupId>org.apache.flink</groupId>
</exclusion>
</exclusions>
</dependency>
java代码如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname(MYSQL_HOST)
.port(MYSQL_PORT)
.databaseList(SYNC_DB) // set captured database
.tableList(String.join(",", SYNC_TABLES)) // set captured table
.username(MYSQL_USER)
.password(MYSQL_PASSWD)
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
env.enableCheckpointing(5000);
DataStreamSource<String> cdcSource = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "CDC Source" + LeagueOcSettleProfit2DwsHdjProfitRecordAPI.class.getName());
1.3、自定义的数据源方式
Flink中可以很方便的使用自定义数据源,只需要实现SourceFunction接口即可。
比如实现一个随机产生某10个学生的N此考试分数的自定义数据源,对每个学生的份数相加,代码如下:
private static class RandomStudentSource implements SourceFunction<Student> {
private Random rnd = new Random();
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<Student> ctx) throws Exception {
while (isRunning) {
Student student = new Student();
student.setName("name-" + rnd.nextInt(5));
student.setScore(rnd.nextInt(20));
ctx.collect(student);
Thread.sleep(100L);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
private static class Student {
private String name;
private Integer score;
public Student() {
}
public Student(String name, Integer score) {
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getScore() {
return score;
}
public void setScore(Integer score) {
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", score=" + score +
'}';
}
}
2、Transformation数据转换
常用的数据转换函数如下:
map :map()算子接收一个函数作为参数,并把这个函数应用于DataStream的每个元素,最后将函数的返回结果作为结果DataStream中对应元素的值,即将DataStream的每个元素转换成新的元素。
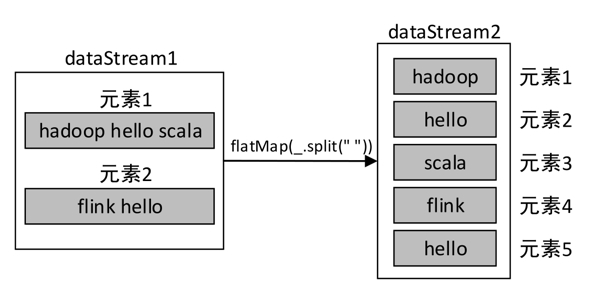
flatMap :与map()算子类似,但是每个传入该函数func的DataStream元素会返回0到多个元素,最终会将返回的所有元素合并到一个DataStream。
filter :通过函数filter对源DataStream的每个元素进行过滤,并返回一个新的DataStream。
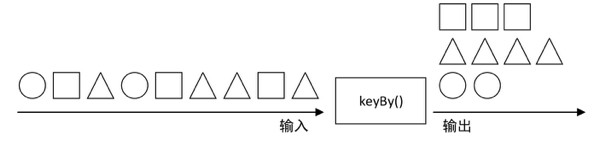
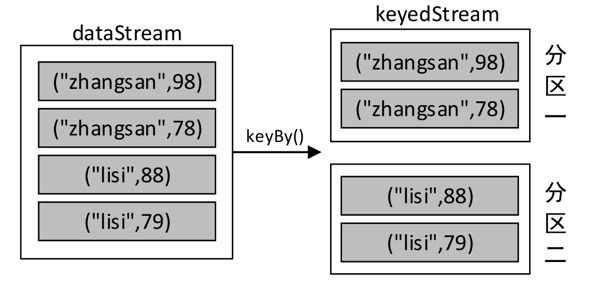
keyBy :keyBy()算子主要作用于元素类型是元组或数组的DataStream上。使用该算子可以将DataStream中的元素按照指定的key(指定的字段)进行分组,具有相同key的元素将进入同一个分区中(不进行聚合),并且不改变原来元素的数据结构。
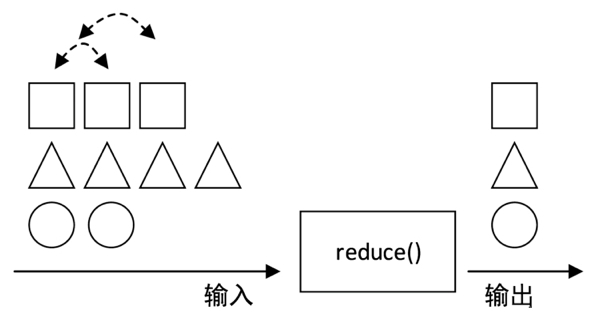
reduce :reduce()算子主要作用于KeyedStream上,对KeyedStream数据流进行滚动聚合,即将当前元素与上一个聚合值进行合并,并且发射出新值。该算子的原理与MapReduce中的Reduce类似,聚合前后的元素类型保持一致。
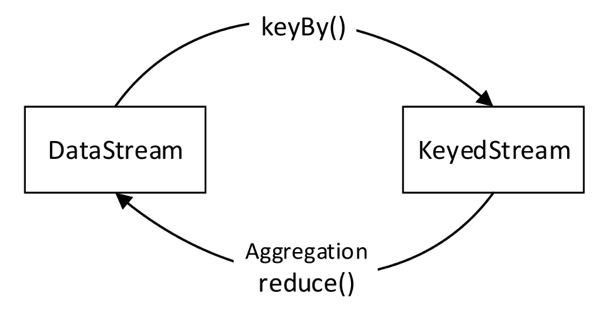
aggregation :aggregation是聚合算子,类似的还有:reduce、sum、max、min。Aggregation算子作用于KeyedStream上,并且进行滚动聚合。与keyBy()算子类似,可以使用数字或字段名称指定需要聚合的字段。keyBy()算子会将DataStream转换为KeyedStream,而Aggregation算子会将KeyedStream转换为DataStream,类似下图:
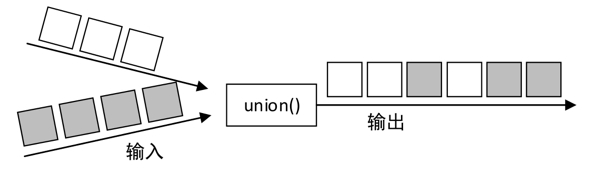
union :union()算子用于将两个或多个数据流进行合并,创建一个包含所有数据流所有元素的新流(不会去除重复元素)。
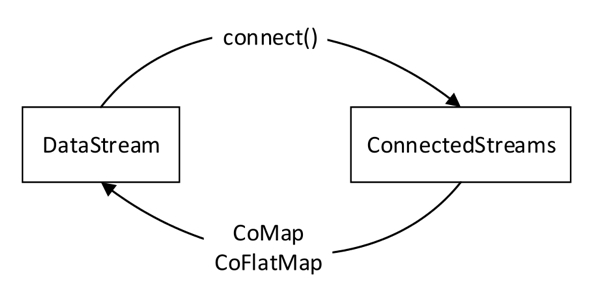
connect :connect()算子可以连接两个数据流,并保持各自元素的数据类型不变,允许在两个流之间共享状态数据。connect与union有几点区别:
- union()要求多个数据流的数据类型必须相同,connect()允许多个数据流中的元素类型可以不同。
- union()可以合并多个数据流,但connect()只能连接两个数据流
- union()的执行结果是DataStream,而connect()的执行结果是ConnectedStreams;ConnectedStreams表示两个(可能)不同数据类型的连接流,可以对两个流的数据应用不同的处理方法,当一个流上的操作直接影响另一个流上的操作时,连接流非常有用。可以通过流之间的共享状态对两个流进行操作。
- 与流的转换:
3、Sink数据输出
3.1、Sink简介
Sink这个词很形象,中文意思“水槽”,寓意:数据流像水一样,源源不断的,经过水槽流向各种目的地。
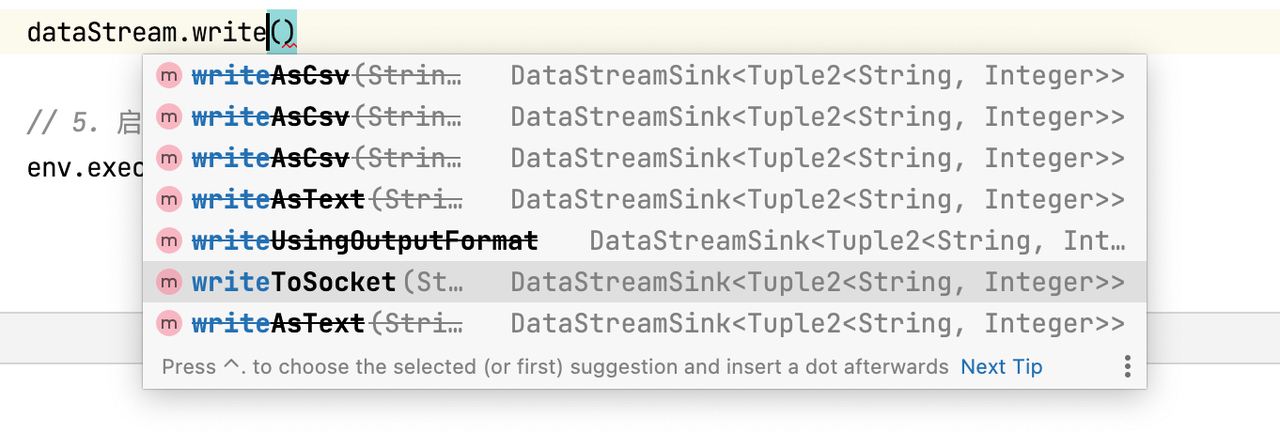
Flink可以使用DataStream API将数据流输出到文件、Socket、外部系统等。Flink自带了各种内置的输出格式,比如writeAsText()、writeAsCsv()等,但是已经过时,如下:
官方鼓励使用addSink()方法,调用自定义接收函数,如下:

3.2、自定义Sink
Flink也可以与其他系统(如Apache Kafka、doris等)的Sink集成在一起,这些系统已经实现了自定义Sink函数。也可以完全自己自定义Sink。并且,通过addSink()方法可以参与到Flink的检查点(Checkpoint)中,以实现“精确的一次”语义。
自定义Sink只需要实现SinkFunction,例如上面的例子中(随机生成学生分数),现在是直接print出来信息,改造成自定义Sink的方式之后,代码如下:
public class AlertSink implements SinkFunction<SourceSourceDemo.Student> {
private static final long serialVersionUID = 1L;
private static final Logger LOG = LoggerFactory.getLogger(AlertSink.class);
@Override
public void invoke(SourceSourceDemo.Student value, Context context) {
LOG.info("自定义sink" + value.toString());
}
}
// transformedStream.print("result =======").setParallelism(1);
transformedStream.addSink(new AlertSink());
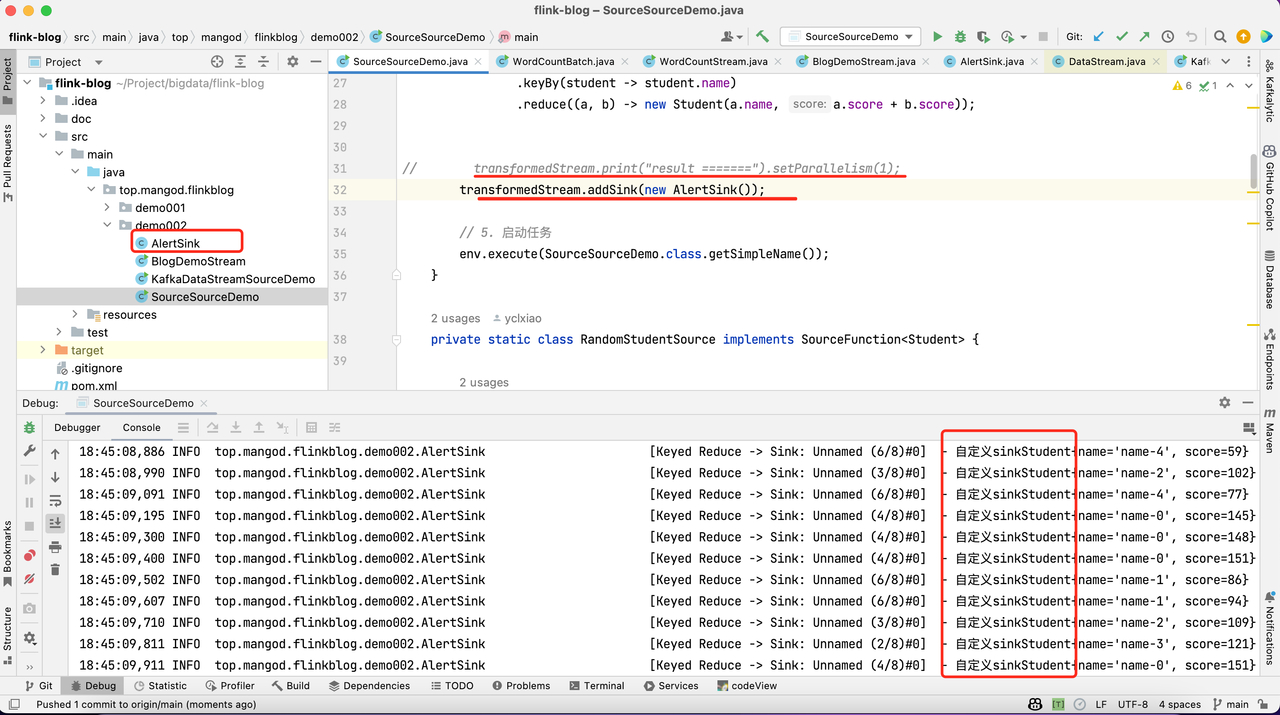
截图如下:
4、代码地址
本篇完结!感谢你的阅读,欢迎点赞 关注 收藏!!!
原文链接: http://www.mangod.top/articles/2023/08/03/1691059784552.html、https://mp.weixin.qq.com/s/XICBfneJWFe4quwf3kRQXQ

标题:Flink DataStream API-数据源、数据转换、数据输出
作者:程序员半支烟
地址:http://mangod.top/articles/2023/08/03/1691059784552.html