 关于我
关于我
Zipkin的介绍以及整合实现
主要介绍如何在spring cloud项目中使用zipkin。以及将调用链路信息通过kafka存储到elasticsearch中,最终可以通过zipkin的ui查看调用链路信息。
核心概念以及原理介绍
traceId:
一次请求全局只有一个traceId。用来在海量的请求中找到同一链路的几次请求。比如servlet服务器接收到用户请求,调用dubbo服务,然后将结果返回给用户,整条链路只有一个traceId。开始于用户请求,结束于用户收到结果。
spanId:
一个链路中每次请求都会有一个spanId。例如一次rpc,一次sql都会有一个单独的spanId从属于traceId。
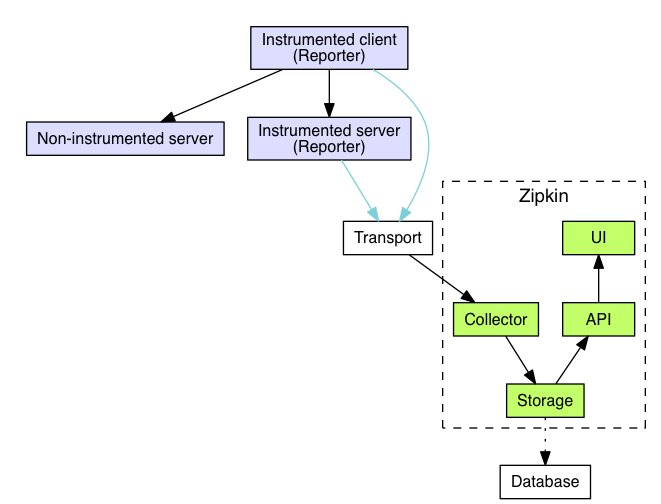
Zipkin的工作过程
当用户发起一次调用时,Zipkin 的客户端会在入口处为整条调用链路生成一个全局唯一的 trace id,并为这条链路中的每一次分布式调用生成一个 span id。span 与 span 之间可以有父子嵌套关系,代表分布式调用中的上下游关系。span 和 span 之间可以是兄弟关系,代表当前调用下的两次子调用。一个 trace 由一组 span 组成,可以看成是由 trace 为根节点,span 为若干个子节点的一棵树。
Zipkin 会将 trace 相关的信息在调用链路上传递,并在每个调用边界结束时异步的把当前调用的耗时信息上报给 Zipkin Server。Zipkin Server 在收到 trace 信息后,将其存储起来。随后 Zipkin 的 Web UI 会通过 API 访问的方式从存储中将 trace 信息提取出来分析并展示。
大致流程图
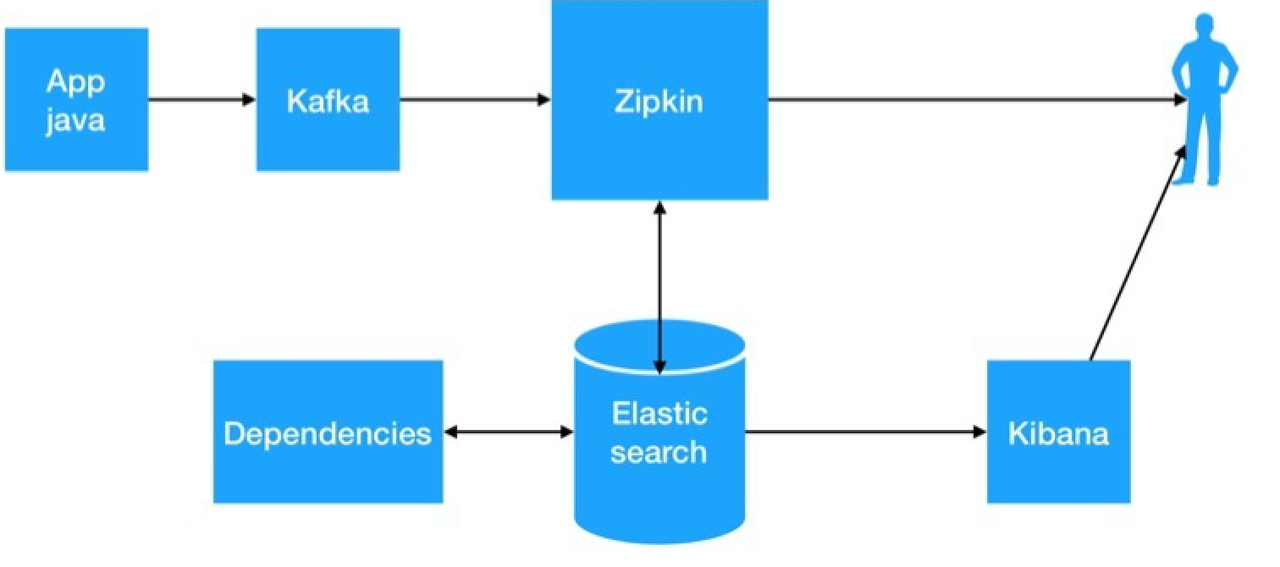
实现步骤
一、本地安装启动依赖的中间件
- rabbitmq安装启动
- zookeeper安装启动
- kafka安装启动
- elasticsearch安装启动
- zipkin-server安装启动
二、demo项目集成和启动
项目中集成以下配置:
项目使用的版本:
SpringBoot: 2.1.4.RELEASE
SpringCloud: Greenwich.SR1
启动步骤:
- 启动eureka
- 启动waiter-service
- 启动barista-service
- 启动customer-service
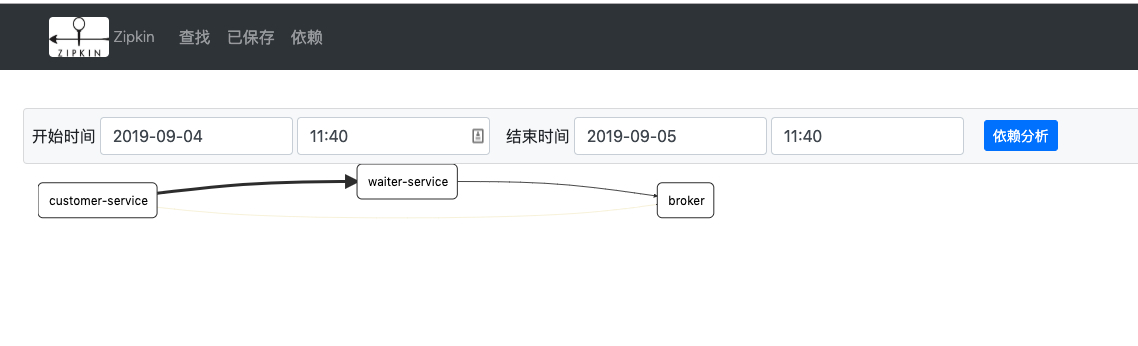
三、调用zipkin UI界面
访问zipkin:http://localhost:9411/zipkin/
![es里存储的信息
项目地址
https://github.com/yclxiao/sc-sleuth.git
遇到的问题
主要是是用外部存储之后,zipkin的ui界面,无法显示调用依赖信息,解决方式:主要通过zipkin-dependencies.jar来解决
- 下载zipkin-dependencies.jar,地址:https://repo1.maven.org/maven2/io/zipkin/dependencies/zipkin-dependencies/2.3.2/,
zipkin-dependencies实则是个可执行的jar文件,有个main入口,执行时,相当于跑了一次任务,生成了对应的依赖关系,存储到了elasticsearch中,下次如果还需要重新生成,在执行此命令:
STORAGE_TYPE=elasticsearch ES_HOSTS=localhost:9200 java -jar zipkin-dependencies-2.3.2.jar
- 同时可以在elasticsearch中查看到新的依赖关系的索引
解决链接:
Zinkin进阶篇-Zipkin-dependencies的应用
参考链接
Spring Cloud实战系列(七) - 服务链路追踪Spring Cloud Sleuth
Spring Cloud 分布式链路跟踪 Sleuth + Zipkin + Elasticsearch【Finchley 版】
Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
使用Spring Cloud Sleuth、Zipkin、Kafka、Elasticsearch实现分布式追踪
SpringCloud(Finchley)整合sleuth、zipkin、kafka、es
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>